Adept Fuyu-Heavy是一种新型的多模态模型,专为数字代理设计。据称,它是世界上第三大能力超强的多模态模型,仅次于GPT4-V和Gemini Ultra。这种模型特别擅长理解用户界面,能够解释和操作各种软件和应用程序的界面,..
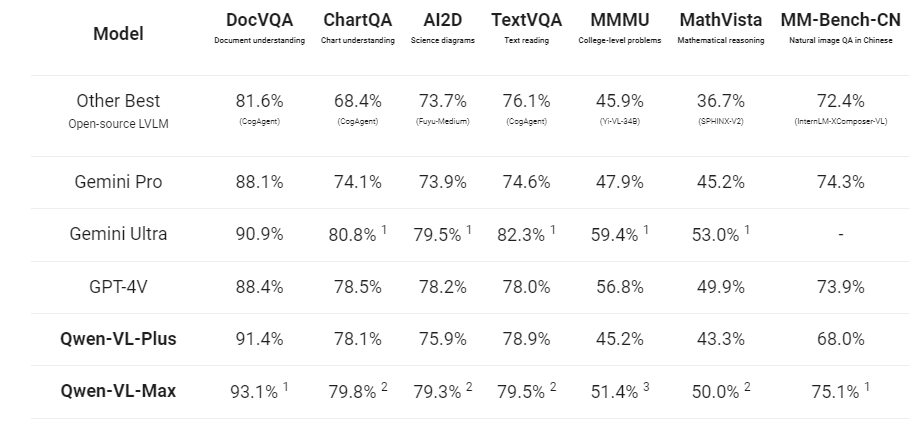
阿里巴巴的多模态模型Qwen-VL经过升级更新,推出了Qwen-VL-Plus和Qwen-VL-Max版本。这两个版本在多个文本-图像多模态任务上与Gemini Ultra和GPT-4V相当。试用地址:https://huggingface.co/spaces/Qwen/Qwen-VL-MaxQw..
划重点:???? VILA 是一个在大规模交织图像文本数据预训练的视觉语言模型,能够实现视频理解和多图像理解功能。???? VILA 发布了具备视频理解功能的 VILA-1.5,支持多种模型规模:3B/8B/13B/40B。???? VILA 通过 TinyC..