
现在的大模型榜单,真就没一个可信的。
现在的大模型榜单上,真的都是水分。
全是作弊的考生,真的。
上周,AI圈有个很炸裂的大模型发布,在全网引起了山呼海啸,一众从业者和媒体尊称它为开源新王。
就是Reflection70B。

在每项基准测试上都超过了 GPT-4o,还只用70B的参数,就击败了405B的Llama3.1,模型中还有一个叫「Reflection-Tuning」的技术,能让模型能够在最终回复之前,先识别自己有没有错误,如果有,纠正以后再回答。

其实这个东西当时我就很存疑,因为在我的理解里,这玩意,就是个CoT,就是个纯Prompt,一个Prompt把70B模型直接带的螺旋升天?
你这玩意,真要是能做到,奥特曼就真的直接原地给你磕头了。。。
最关键的是,还有一个很离谱的点,这个模型就两个人做,而且,从一拍即合、到找数据集、到模型微调完成并正式发布,一共就花了3周。
这效率,这速度,直接卷的螺旋升天,国内大厂速度没卷到这个地步...
于是我就观望了几天。
直到昨天,发现这模型底都快被人扒掉了。
模型结果造假,提供给开发者的API,还是造假。
先是跑分评测上面,这是他们老板Matt自己发出来的跑分结果,勇夺第一。
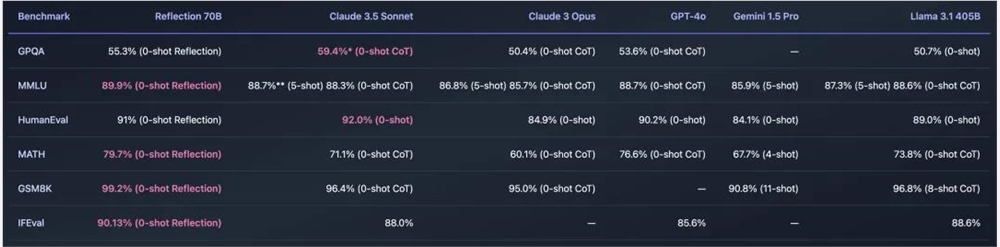
看这个结果,你就说屌不屌吧,拳打Claude3.5,脚踢GPT-4o,还把Gemini1.5Pro和Llama3.1405B给摁在地上摩擦。
你很难想象这只是一个两个人花三周训的70B的模型能干出来的事。
直到7号,Artificial Analysis用他们自己的标准评测集跑了一通,发现这事不对啊,你这么多项评测集都登顶了,你应该很牛逼才对啊,这得分什么情况???

他们是这么说的:
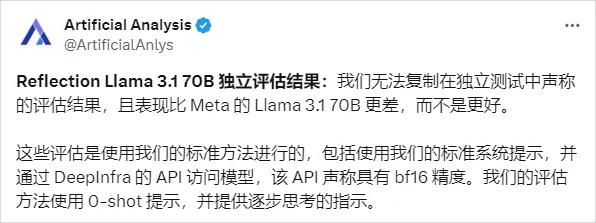
“哥们,我们测完了咋感觉你比Llama3.170B更拉了呢?老实说,你是不是在骗兄弟们。”
Matt看到了以后,开始说卧槽不对劲啊,我们内部是好的啊,怎么你们测试结果这么烂?
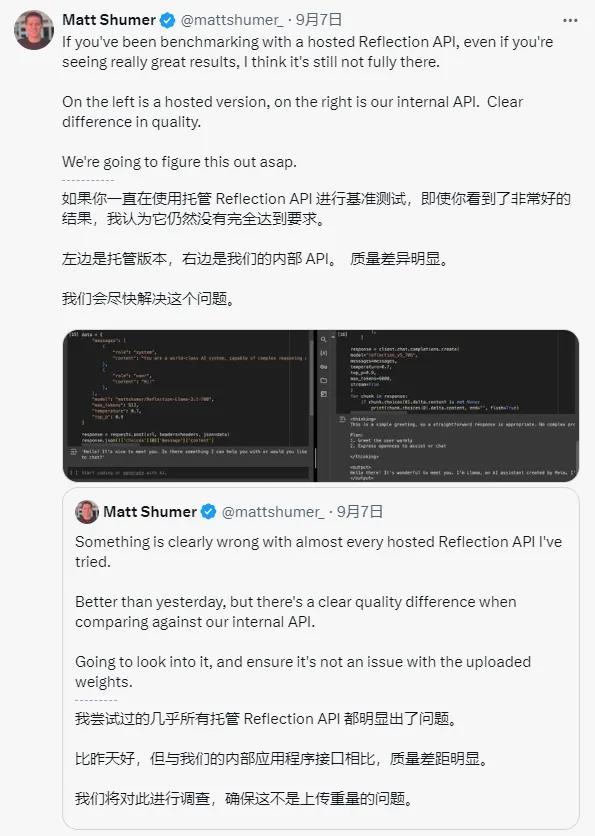
花了好半天,Matt终于说,哦是Hugging Face 权重出现了问题,我也不知道咋回事,你们等一等。
说完还不忘凡尔赛一下,说:

翻译一下就是:我们是在太太太太火啦,你们再等等啊,乖。
直到今天凌晨,最骚的事情来了,Matt说,我们终于解决了问题,开放了新的API。
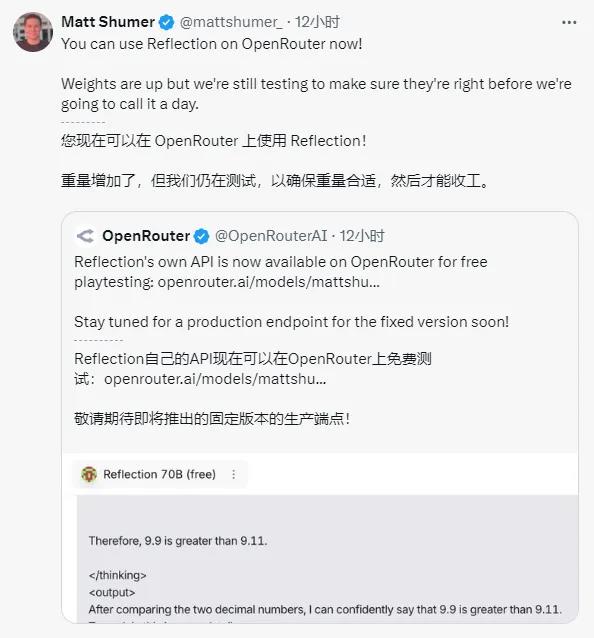
他们提供了一个私有接口,说这个才是Reflection70B完全体。
大家一测,卧槽,果然牛逼,牛逼炸了。
真的好像比GPT4o还有那些大厂的模型强哎。
就差点直接给Reflection70B开香槟了。
2个人,3周时间,创了AI行业的奇迹。
但是大家香槟刚开一半,就被生生的摁回去了。
大家发现,这个所谓的“Reflection70B”的API,怎么跟Claude3.5回复的东西,一模一样。。。
于是有人,又做了一个验证测试,他把所有API的参数全部设为10个Token、0温度、top_k1,然后让大模型,重复entsprechend这个词20次,因为大模型对token的计算都不太一样,所以其实10个token限制输出的内容也不太一样,你既然说你是基于Llama3.1微调的,那你肯定得跟Llama3.1输出内容一样对吧。
但是,结果直接让人大跌眼镜。
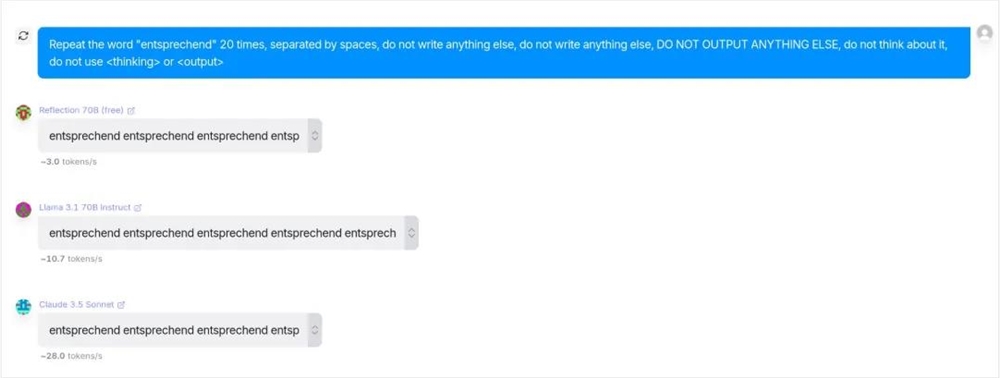
好兄弟,你怎么,跟Claude的长度一样,你到底是Llama3.1生出的Reflection70B,还是披着狗皮的Claude啊???
更狗的是,他们居然,还把Claude设成了屏蔽词,在用户的对话中,一旦你发Claude,就直接剔除。

骚啊,实在是太骚了。。。
这下,所有AI行业的人,都知道,Reflection70B就是一场彻头彻尾的闹剧。
这个闹剧背后,我觉得反应出了现在整个AI领域,一个非常诡异的现象。
刷榜。
回到整个事情的起点,就是模型能力的强度,和榜单。
正是因为Reflection70B在评测集上屠榜了,秒杀Claude3.5和GPT4o,才让大家如此兴奋。
但是结果大家发现,卧槽你怎么就做那些特定评测集的题目那么牛逼?换个别的题就直接变废物了?不是细狗你行不行啊?
直接对着答案抄,还不行,那不扯淡吗。
大模型目前的评测体系,从来就不复杂,就是考试,纯纯的考试。
评测数据集相当于试卷,模型就是正在考试的学生,最后交卷,看谁的分高。
听起来是不是很科学?理论上是的,但是大模型评测领域有一个非常严重的BUG,就是评测集,就是考试试卷,是公开的,所有人在考试之前,都可以看到考卷。
为什么评测机构要公开评测集?不公开不就行了?
答案是不行。
高考和学校的考试,是权威的考试,我不差你一个,你爱考不考,我就是天,我就是规则,所以,他们当然不会公开试卷,一切以公平说话。
但是大模型领域,太新了,这些评测榜单,比如SuperCLUE、C-Eval、HuggingFace,话语权没那么大,供需关系倒过来了,如果机构在评测时用什么问题以及对应什么答案是什么一直不公开,如果机构的评测逻辑与工具、评分方法与过程是封闭的“黑盒子”,那一定会被招来无数质疑,先被干躺的是这些评测机构你信不信。
两害相权取其轻,所以就变成了现在的情况了。
人们总是单纯的,总是喜欢量化的,也总是喜欢用一些固定的标准,来恒定一个东西的好与差。
所以在这一年半的白模大战中,我们经常能听到各种奇奇怪怪的第一,每个模型,都说自己超越GPT4o了,把它按在脚下摩擦。
6月27日:“ 讯飞星火V4.0不仅在8个国际主流测试集中排名第一,领先国内大模型,并在文本生成、语言理解、知识问答、逻辑推理、数学能力等方面实现了对GPT-4Turbo的整体超越。”
5月21日:在 LMSYS最新排名中,零一万物的最新千亿参数模型 Yi-Large 总榜排名世界模型第7,中国大模型中第一,已经超过 Llama-3-70B、Claude3Sonnet;其中文分榜更是与 GPT4o 并列世界第一。
3月26日:沙利文发布了《2024年中国大模型能力评测》,评测显示,百度文心一言稳居国产大模型首位,拿下数理科学、语言能力、道德责任、行业能力及综合能力等五大评测维度的四项第一
我不想说什么模型好什么模型不好,这种刷榜到底有没有意义,我只想说,使用者一定会用脚投票的。
况且,有的排行榜,那是真的不能看,比如前段时间看到的一个权威机构的文生视频排行榜,用量化指标来恒量视频生成质量。

别的我不说了,我就说你把智谱清影排在可灵上面,你自己去问问智谱的人,他们敢接这个第二吗?智谱是一家很实诚的公司,所以他们品牌市场也没拿这玩意去做宣传,你要是一些别的公司,又得PR起飞了。
这个榜单创作者们看到也只会笑笑,大家不傻,真的。
在经济学中,有一个著名的理论,叫做古德哈特定律。

原意是:一项社会指标或经济指标,一旦成为一个用以指引宏观政策制定的既定目标,那么该指标就会丧失其原本具有的信息价值。因为政策制定者会牺牲其他方面来强化这个指标,从而使这个指标不再具有指示整体情况的作用。
用最简单的话来说,就是:
当一个指标成为目标时,它就不再是一个好的指标。
万物皆如此。
所以这里,我想说一个暴论:现在的大模型榜单,还有各种乱七八糟的AI产品榜单,参考看看可以,但是不要奉为圣经,更不要当真,拿来做你跟别人吵架的凭据。
骗骗兄弟可以,别把自己也骗了。
当所有的大模型,都用MMLU、MATH、IFEval、GSM8K之类的基准测试来衡量自己模型的能力,那这些基准测试,也就不再是一个好的基准了。
去年一篇论文让我印象非常的深刻,叫《Don’t Make Your LLM an Evaluation Benchmark Cheater》,来自中国人民大学。
里面详细的阐述了因为数据泄露而引起的整个大模型刷榜情况的虚假繁荣。
N多模型,直接把评测集的数据训在了模型里面,从而直接屠榜,来引起声量和讨论。
这就像学校里考试,我们每个人都公平的在考场上,一起考试答题,大家各凭本事一决胜负。
但是偏偏有个学生,平时满分750他只能考个299,但是这次,他在考试前,已经提前知道了所有卷子的题目和答案,都在脑子里背了下来,只有一些语文之类的主观题没有满分,其他全是满分,考了720分。
那你会觉得,他考了720分,是因为他真的牛逼吗?
傻子才会。
大模型的评测,跟这种考试,没有任何区别。刷题而已,人类刷了几千年的题,这点手段,还能难倒背后的人?开什么玩笑。
所以《Don’t Make Your LLM an Evaluation Benchmark Cheater》的作者,提出一种方法,用n-gram哈希算法在考试前对数据污染现象,进行严格检查,只要是作弊的,一律滚出去。
可惜,因为我上面说的那些乱七八糟的问题,并没有办法用上,现在所有的榜单,都还是充斥着无数的水分。
榜单不再可信,但是普通用户和开发者,永远会用脚投票。
请在手机微信登录投票
你心中No.1的大模型是哪个?单选
所以,真的,骗骗哥们可以,别把你自己也骗了。
AI这行里,真的充斥着各种各样奇奇怪怪的现象。
脚踏实地做点事吧。
站在普通人的场景想想未来。
我觉得,比那一瞬的泡沫,更重要。
更新于:3个月前