
蚂蚁集团开源向量索引库VSAG,支持千维以上向量存储
9月5日,在2024Inclusion·外滩大会“从DATA for AI到AI for DATA”见解论坛上,由蚂蚁集团发起的,旨在提高数据库与大模型应用开发效率的“星辰智能社区”新发布了两个项目:AI原生数据应用开发框架DB-GPT新版本与向量索引库VSAG。
DB-GPT是一个开源的AI原生数据应用开发框架。在数据库领域,如何增强和大语言模型的交互任务,减少大模型的幻觉,为用户提供可靠并且安全的数据理解和分析能力,仍然是一项极具挑战的工作。DB-GPT通过开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单便捷。
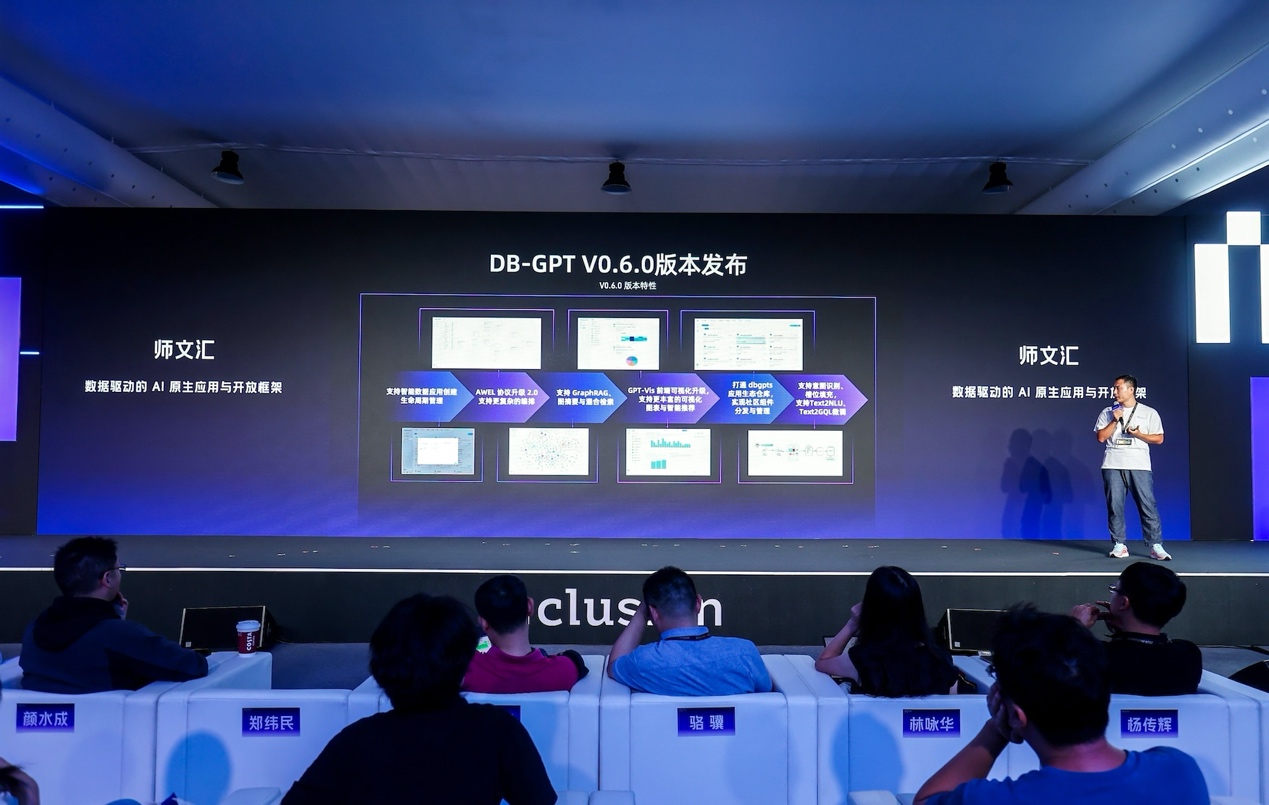
蚂蚁集团资深技术专家师文汇介绍DB-GPT新版本六大特性
本次开源的新版本 DB-GPT v0.6.0,完整支持了数据驱动的AI原生应用生命周期管理(AI Native Data Apps-dbgpts)以及AI原生应用仓库,方便开发者构建、发布、分享AI Native Data Apps,还新增了六大特性,包括将AWEL协议升级至2.0,支持更复杂的编排;结合TuGraph,能支持图的构建与检索,进一步增强检索的准确性与召回的稳定性,以减少大模型的幻觉,在同样的检索效果下,构建Graph的成本比业界的方案少50%的Tokens;支持Agent Memory,如感知记忆、短期/长期记忆、混合记忆等;支持意图识别、槽位填充,支持Text2NLU、Text2GQL微调等。
社区还新发布向量索引库VSAG。VSAG是蚂蚁集团在向量数据库上一系列的工程优化与向量索引的算法改进成果,适用于高维向量的存储和计算优化,并能提供 C++ 和 Python 的接口以便使用。VSAG已在蚂蚁内部百亿数据量级业务上使用,在保证同样的召回率情况下,VSAG 可以通过量化和基于磁盘的重排技术,将内存消耗降低到 HNSW(最流行的向量索引)的1/10,从而实现生产部署成本的大幅降低。VSAG将结合DB-GPT,让RAG的构建更加简单、高效,同时VSAG作为独立开放的向量引擎,也将支持LangChain、LlamaIndex构建RAG应用。

蚂蚁集团资深技术专家师文汇介绍新开源的向量索引库VSAG
“星辰智能社区”由蚂蚁集团发起,专注于AI时代数据智能技术的探索,社区在GitHub上已获得17k Star数,核心成员来自蚂蚁、阿里、美团、京东、唯品会等科技公司和知名海内外高校硕博在校学生。目前已有超过50万用户正在学习和使用DB-GPT,社区活跃人数近7000人,开发贡献者130人。
更新于:3个月前