
崔大宝:大模型降温背后的难点、卡点、节点
进入2024年,大模型似乎有熄火之势:资本市场,与之关联的概念炒不动了,英伟达股价动辄暴跌重挫,引发“泡沫戳破”的担忧;
消费市场,BATH们的推新活动少了,产品更新迭代的速度慢了,民众的关注度降了……
热闹的大概只剩下两场酣仗:自5月15日字节跳动宣布“以厘计费”,打响国内大模型“价格战”的第一枪,百度文心、讯飞星火、阿里通义、腾讯元宝等纷纷跟进;
同时,地铁、写字楼、机场等白领人群密集区域,百度文心、讯飞星火、阿里通义、腾讯元宝、华为盘古的Slogan,你方唱罢我登台,贴脸营销如枪林刀树。
“海水”与“火焰”交融的场面,不得不让人思考,大模型的出路究竟在哪里?难点、卡点、节点又是什么?
难点:盈利难落地难
强如OpenAI,也面临“恰饭”的难题。
援引外媒报道,OpenAI预估亏损50亿美元,全年运营总成本高达85亿美元,照此估算,其现金流大概率在一年内耗尽。
而在一篇题为《How does OpenAI Survive》的长文中,作者对OpenAI的商业模式产生了质疑:
“OpenAI的营收在35亿至45亿美元之间,但其运营亏损可能高达50亿美元,其收入远远无法覆盖成本。而为了推出下一代的大模型GPT5,OpenAI需要更多的数据和算力,这又是一大笔花费。”
说千道万,靠着“碎钞式”的大力出奇迹后,大模型却仍未找到一条合理的盈利路径。
据《节点财经》观察,市面上的大模型,大部分都采取To C+To B,即会员订阅+开发者API调用“两条腿”走路。
但无论是To C,还是To C,能一上来就产生付费的寥寥无几,若再刨除重负的减项,多半是鼻子大过脸。
以本土大模型先行者百度为例,2024年Q1,其云业务收入为47亿元,同比增长12%,其中6.9%来自外部客户使用大模型及生成式AI相关服务,约为3.24亿元。
而在2023年Q4,大模型为百度云贡献了6.6亿元增量收入。
这是国内唯一披露大模型收益的厂商,本身又是家大业大,有底气拼到底的巨擘。但只谈创收,忽略创利,就是耍流氓。
可想而知,其余不敢明示账目的选手,内心有多迷茫、煎熬。
不挣钱,难挣钱的背后,是大模型落地难的窘境。
虽然大佬们高呼“ChatGPT”的问世是“iPhone时刻”,第四次工业***,新一代的“火”和“电”,但坦率地讲,当下大模型还有很多局限性,包括认知偏差、能动性欠缺、泛化性能弱、幻觉等。
比如,数值运算就是大模型明显的弱项,或者说大模型是妥妥的“文科生”,做数学题的智商可能连二、三年级的小学生都不如。
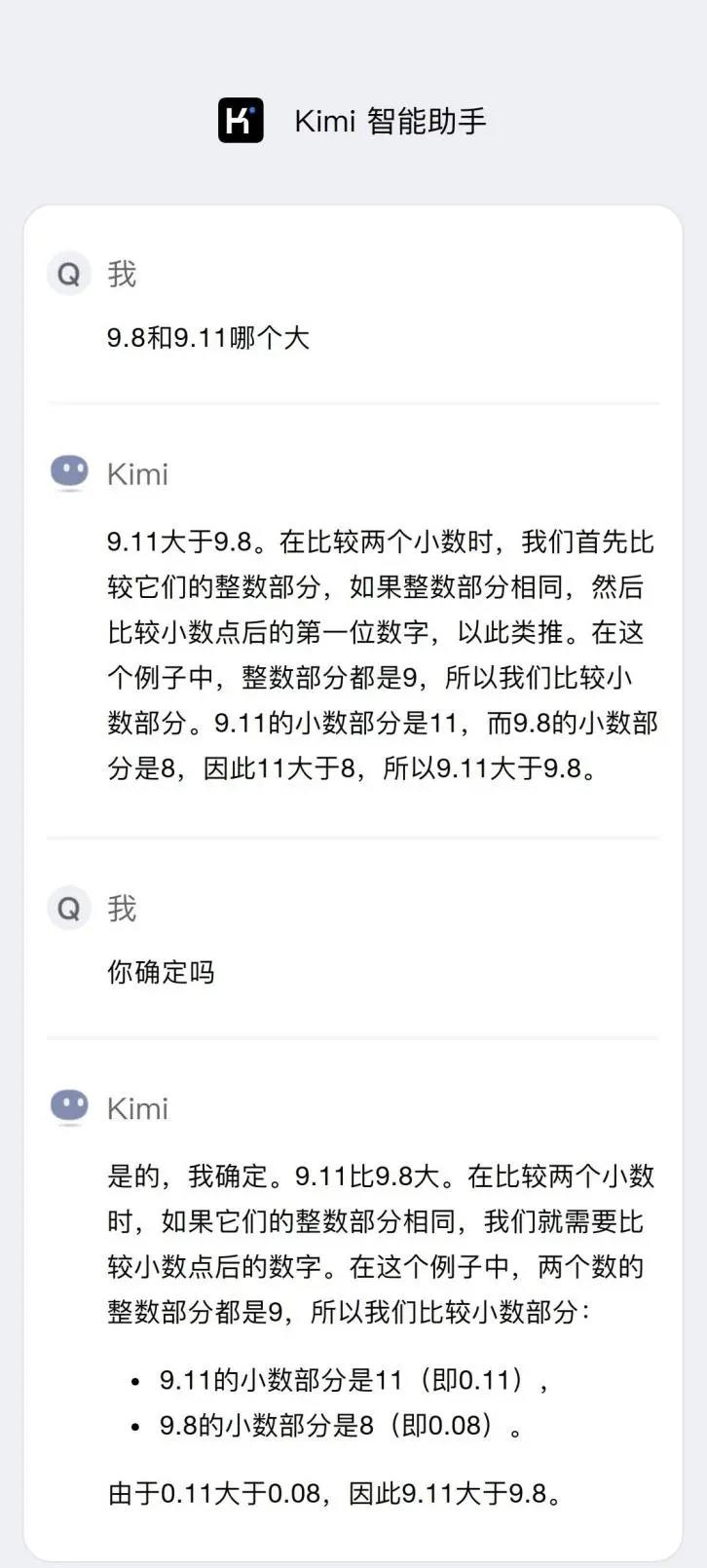
《节点财经》亲测,在Kimi输入:“9.11和9.8哪个大?”一顿啰嗦后,Kimi给出了完全不正确的答案。
比如,大模型资料更新不及时,必须外挂知识库才能在一定程度上缓解这个痛点,并且还是无法完全解决“一本正经地胡说八道”的尴尬。
前几天刷屏的SearchGPT,就在各地网友兴致勃勃等待灰测展现AI搜索的“洪荒之力”时,《大西洋月刊》浇了一盆冷水,眼尖的记者发现:
问的是关于“八月份北卡罗来纳州的布恩音乐节”的细节,SearchGPT的回答分为5条,3条里包含事实错误——有的是把举办日期弄错,有的是把距离和车程搞混,有的是把场馆网址张冠李戴。
再如,大模型绝对是“健忘症”患者,我们在和它对话时,尤其是多轮对话时,难免要化身“复读机”,一遍一遍重复相同的话术。
而在B端,因为实战经验不足,生分于对方的Know-How,加之环境的复杂多变性,大模型面临的挑战更艰巨。某业内人士表示,迄今大模型在行业中尚没有一个成熟的案例。
卡点:数据、算力、成本
深入肌理地分析,大模型的“落地难”又与自身的三大卡点:数据、算力、成本息息相连。
➊卡在数据
如果把大模型比作一头巨兽,那它的显著特征之一便是“不停进食”:需要高质量、大面积的语料做长久期、高频次地投喂、催肥。
换言之,“食物”的品质、多寡、新鲜度、多样性等,决定了大模型的迭代进度和学习效果。
无疑,这对数据的挖掘、获取提出严峻考验,关系到各方的权益保障、利益分配、版权归属等,通常涉及到敏感信息时,数据的清洗、标注、脱敏又会很繁杂。
前阵,免费网文APP番茄小说因一份“AI协议”引发轩然大波。根据该份协议,平台可以将签约作品,含名称、大纲、简介、章节等,作为“哺育”AI大模型的素材,用于各种应用场景,如智能对话、智能文本创作等。
不过,这一举动遭到作者的普遍反对,认为其不仅威胁网络写手的生计,还损害了原创内容的价值,甚至发起联合断更以示抗议。
➋卡在算力
如果把AI链路比作一间工厂,那么算力便是维持工厂运转,量级夸张且进价不菲的“燃料”(煤、石油、电力等)。
公开资料显示,初始ChatGPT匹配的算力是1万块英伟达A100(AI芯片),花费超过7亿元。后续调优每天消耗的算力大概是3640PFLOPS,即7至8个算力达500PFLOPS的Data Center的支撑,整体基建开支以百亿计。
按照广发证券的测算,在暂不考虑软件层面算法优化的前提下,本土AI大模型在训练与判断、预测阶段所需算力,相当于1.1万台或3.8万台(乐观假设下)高端AI服务器,大致对应约126亿元到434亿元的资金体量。
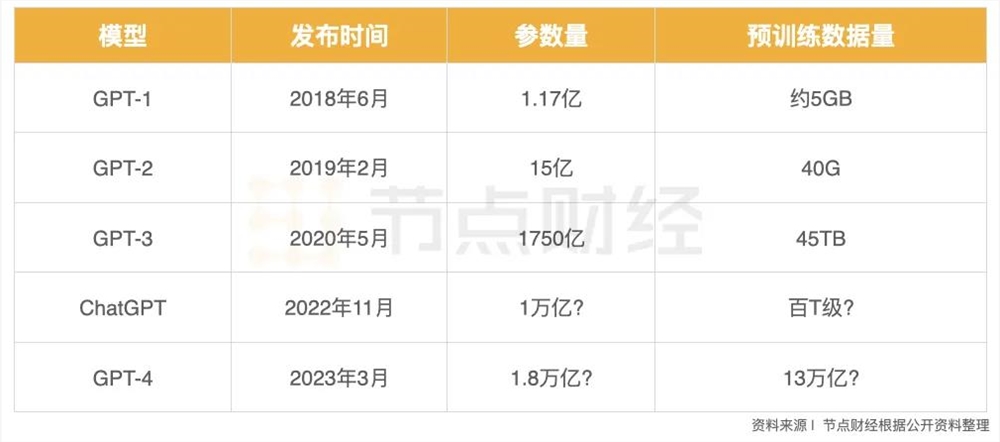
进一步地,随着大模型规模状大,算力需求会倍数递增,已然超越硬件的摩尔定律。据悉,ChatGPT从1.0到3.0,参数量从1.17亿狂飙到1750亿。
而目前,我们在算力这块既面临外部“卡脖子”,内部建设又相对落后,碎片化、传输慢、协同难、人才紧缺等“痼疾”亟待突破,导致大模型的实效逊于国外。
“大模型只有两个梯队,OpenAI和Others,国产用哪家都一样”,多位AI从业者谈道。
➌卡在成本
大模型“桎梏”于算力,实际也是“桎梏”于成本。
计算机飞入千家万户,售价下探,变得亲民、接地气,很关键;智能手机能人手一部,物美价廉的小米功不可没;新能源汽车的热卖,离不开动力电池的“跳水式”降价……
从人类历史的进程看,任何一项新技术的推广、普及,都离不开对成本的有效、大力压缩、控制。
硬币的背面,是科技发展和工业文明进步共同作用下,制造效率、运算精度提升,人均产值拔高,各类物料愈发便宜等因素集结的强大驱动力,进而减轻C端、B端“太贵了,买还不买”的纠结。
大模型同理,浩大的开支也是其成长途中的“绊脚石”。试想,当生态里只有唯一的“卖铲人”(英伟达)赚钱,赚头还不小,怎么可能持续呢?
好消息是,今年2月末,李彦宏透露,自发布以来,百度不断降低文心大模型在推理方面的成本,已降至去年3月版本的1%。
节点:在产业里“种植”大模型
毋庸置疑,大模型仍有诸多“短板”和缺陷,但新技术的魅力向来在于探索“无人区”,跋涉“深水区”。
很多眼下看似微弱的“火种”,往往都孕育着日后“纳须弥于芥子”的宏壮。尽管迄今为止的大模型,大家都是拿着锤子找钉子,但我们已经看到,其正逐步向产业迈进,尝试扮演了一些浅层的Agent的角色。
最醒目的标识便是,大模型不再坐而论道,只会聊天、写诗、作画,而是起而动之,走出实验室,去往矿区、政务、金融、医药、金融、物流等具体领域,努力兑现自己的终极使命。
比如,在矿区,下井工人常年深陷光线昏暗、浮尘弥漫的环境,叠加经年累月高强度的劳碌,使不少人都患上了风湿、耳鸣等职业病,更甚者,还可能遭遇瓦斯、透水等意外,但矿区作业又十分依赖人力,特别是主运系统巡检。
华为的盘古矿山大模型这时候便派上用场了。其覆盖煤矿的采、掘、机、运、通、洗选等流程下的1000多个细分场景,用AI取代人成为主运智能监测系统的眼睛,能够精准识别大块煤、锚杆等异常情况,异物识别准确率达98%,动作规范识别准确率超过95%,且全时段巡逻助力工作人员,避免因漏检造成的安全事故,缩短停机时间。
京东表示,基座大模型是靠卡训出来的,企业大模型是靠人用出来的。
物流领域,揽收、派送、分拣、辅助,应对突发事件等,快递员每天都背负着繁重的任务,还要熟悉货物处理规程、安全操作标准、客服要求等多达上百个规范,把这些统统记牢,肯定要耗费大把功夫,还容易混淆。
京东言犀大模型的小哥终端助手大大化解了上述烦恼。它告别了只“动脑”的境界,能直接“下手”,快递员动动嘴,小哥终端助手就能立即将送货通知发给客户。如今,小哥终端助手为JD商城近35万自有配送员“效劳”。
再如,零售行业,基于京东言犀大模型的AIGC营销工具“京点点”,不仅可以帮助商家一键出商品图,还支持了超过2000种视觉元素道具;不仅可以丰富吸睛资源和表现力,还能依循商品属性、特点和宣传想要的个性化布局,实时、自主撰写创意卖点、种草文案、直播脚本等。
总的来说,把大模型“种植”在产业里,让大模型在产业里生长、发芽,俨然是现在大厂的共识,必须攻克的难关。长远看,该共识亦如“星星之火”终会燎原旷野。
写在最后
当喧嚣过后,大模型这场豪华游戏,能留在牌桌的玩家,注定只是少数。
面对数据、算力、成本等现实问题,供需两端渐渐回归理性。可以预见,在真“好用”和能“吸金”之间,大模型还有很长的路要走。
更新于:4个月前