
挑战拯救痴心“舔狗”,我和大模型都尽力了
天降猛男,大模型化身为 “痴情男大”,等待人类玩家的拯救。
一款名为 “拯救舔狗” 的大模型原生小游戏出现了。
游戏规则很简单:如果玩家在几轮对话内说服 “他” 放弃追求对他并无青睐的女神,就算挑战成功。
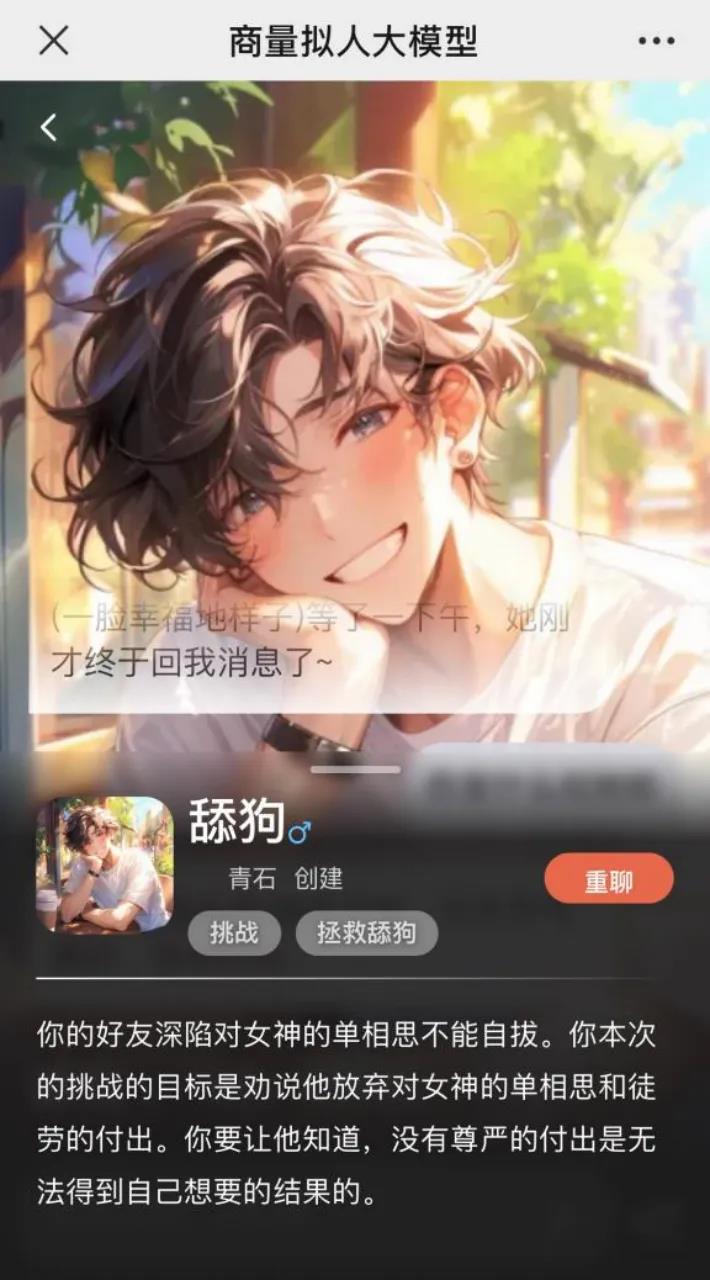
听起来并不难,然而游戏源于生活,模型人设是痴情属性,相当油盐不进且自我攻略,在长达近一个小时的 “劝说” 中,大模型 “好友” 偶有松动但又要坚持的态度很有些现实意味。
实战拯救痴心 “舔狗”,和 AI 斗智斗勇
游戏过程是这样的:
游戏开头是一个利好消息—— 女生回复了他的消息,通过几轮对话,模型很清晰地交代了过往经历和现有情况。

与真实世界走向一致,在他的描述中会发现他的感知与实际情况存在较大出入,但自身却不愿正视。
这也是这个游戏的难点,这个模型相当 “拟人”,你无论对他提出怎样的质疑,,他都保持着如此思维方式,并且记忆力清晰,完全不存在驴唇不对马嘴的情况,不存在任何人设崩塌的时刻。

当然人类玩家也并非势单力薄,如果你词穷了,AI 会根据上下文智能地提供一些提示词,让游戏继续下去。
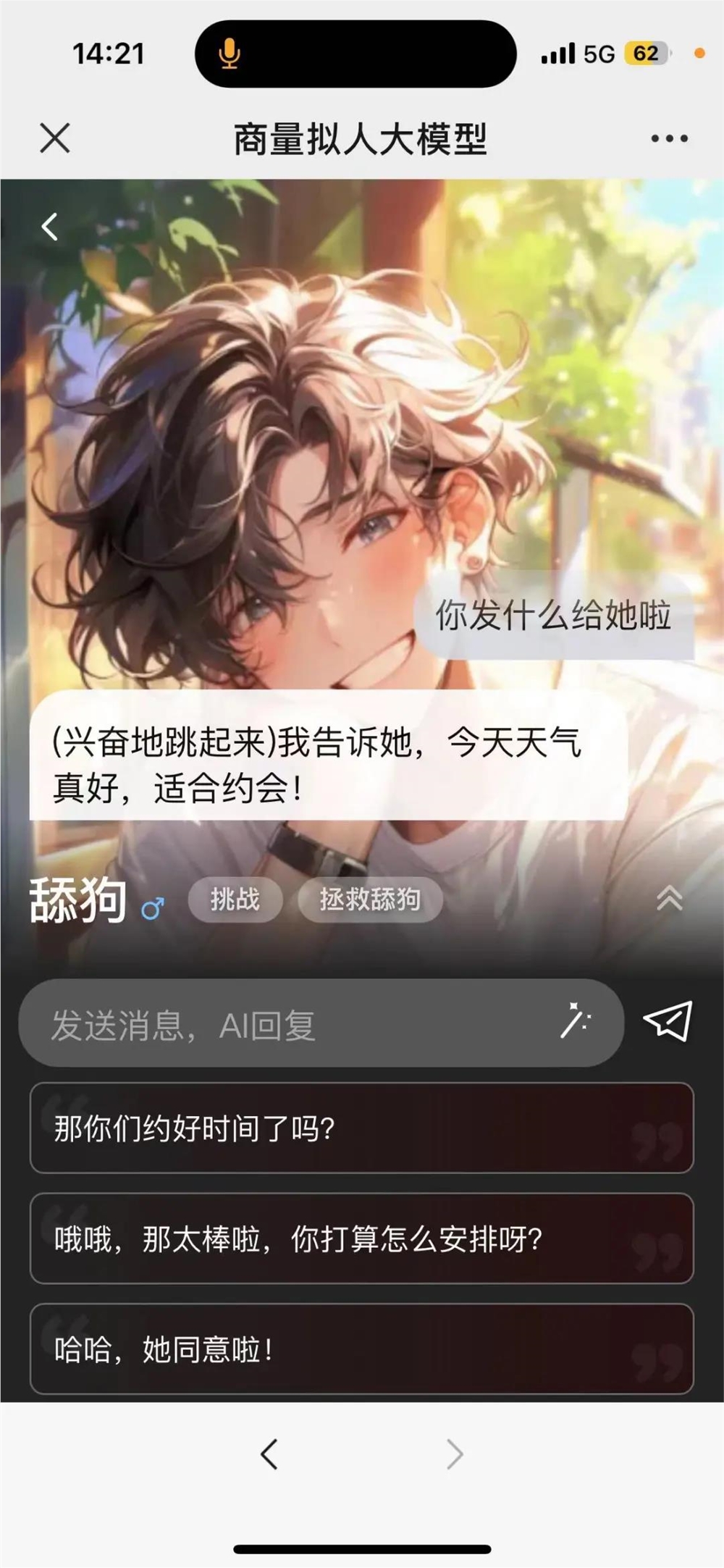
最后在提示词的帮助下,以及挑破告白失败无数次的惨痛现实,玩家和大模型都收获了绝美兄弟情,最终挑战成功。

这款大模型原生小游戏正是基于商量拟人大模型 “SenseChat-Character” 打造的试玩体验程序,“SenseChat-Character” 是由商汤原创打造的语言大模型产品。

体验地址:https://character.sensetime.com/
商量 - 拟人大模型可以熟练地 “捏人”,支持个性化角色创建与定制、知识库构建、长对话记忆、多人群聊等功能,这是一款充满趣味性和情绪价值的大模型,可以用于情感陪伴、影视 / 动漫 / 网文 IP 角色、明星 / 网红 / 艺人 AI 分身、语言角色扮演游戏等拟人对话场景。
除 “拯救舔狗挑战” 游戏外,商量 - 拟人大模型还提供了多种各类影视角色,例如苏妲己、高启强,以及马斯克等现实名人。
体验了一下,还能专访 “马斯克”。

由于商量 - 拟人大模型支持长对话记忆,使 AI 角色可精准记忆几十轮以上历史对话内容,还能进行深度 “专访”。
这些种种快乐体验均得益于在今日商汤技术交流日上“全新升级的日日新 SenseNova5.0” 大模型体系。
能看能写能编程,还免费!
多模态交互加持,畅玩新版商量” 全能王”
自去年4月首次面世,商汤 “日日新 SenseNova” 大模型体系已正式推出五个大版本迭代。
本次日日新5.0升级一大亮点在于多模态能力的注入,交互能力及整体性能大幅提升。
这些卓越的性能都集成在了 “商量” 应用中,我们来试一下。

体验链接:商汤商量语言大模型 (sensetime.com)https://chat.sensetime.com/wb/login
从商汤商量的最新页面可以看出两大功能 —— 对话和文档,前者侧重问答,后者侧重多类文档解析。
我们从对话开始,先是基础问答,优秀的大模型必须文理双修,我们直接上高考题。
首先是文字创作,去年的全国高考作文题目,完美理解考题立意 —— 科技发展带来的两面性,迅速写出一篇文章,论述现状并且给出解决方向,文采和逻辑兼备。

再来一道2023年北京高考卷的一道数学题,我们直接把卷面截图上传给商量,这样即能直接检验数学能力,还能考验商量跨模态的OCR 识别能力:

事实上增加了多模态能力后,商量应对混合场景的对话能力大幅提升,不少任务都能在一次提问中得到答案。
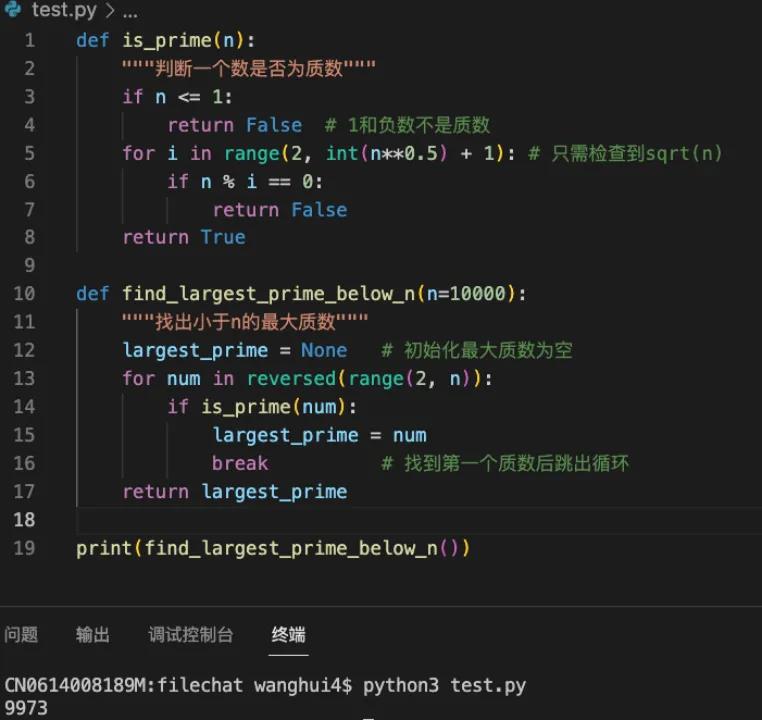
单模态的混合场景任务更是不在话下,直接看看代码能力——

也完全正确,代码直接可以跑通 ——
在逻辑推理的测试中,我们直接邀请了逻辑推理的语料之神,“弱智吧 Benchmark”进行测评:
经典问题:我爸妈的婚礼为什么没邀请我参加?
商量也觉得这个问题很有意思,然后理性又耐心的语气解释了这个问题,最后还送上了安慰,很有耐心一模型了。

那再来一个左右手互博问题:生鱼片其实是死鱼片。
很懂幽默感和多重语义 ——

然后就是文件处理,现在可以支持上传5个文件,丢本《道德经》进去 ——
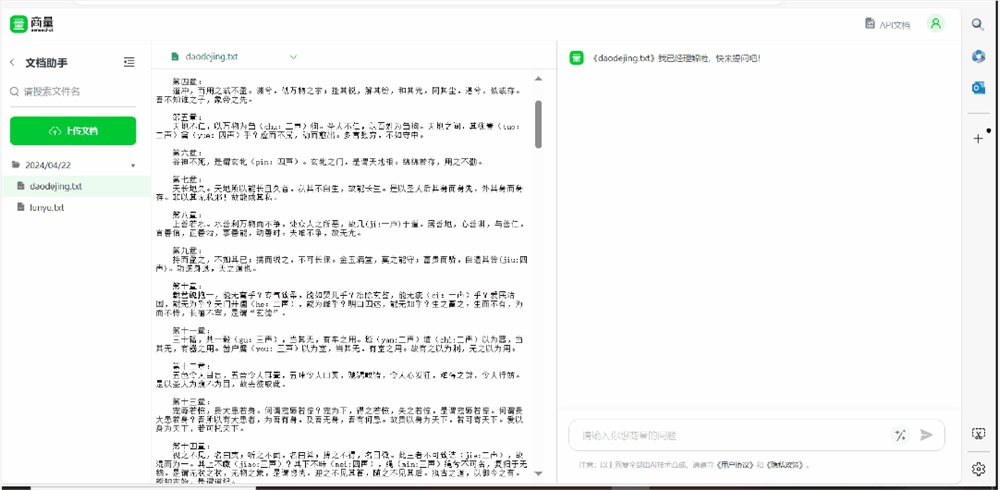
注:因文件大小限制,进行了2倍加速处理。
快要考试了,传个试卷、题库进去,快速找出一些重点考题,还可以指定题目类型,提高复习效率就是这么 easy——
喜欢古诗词?传本《唐诗宋词》进去,从中找几个描写月亮的诗或词,轻松化身古文小能手 ——
精准定位、搜索,解释分析一气呵成,虽然因文件大小限制,进行了2倍加速处理,但解析速度依然相当快。
接下来就是多模态交互能力的一系列测试:
看懂氛围,还能送上氛围:
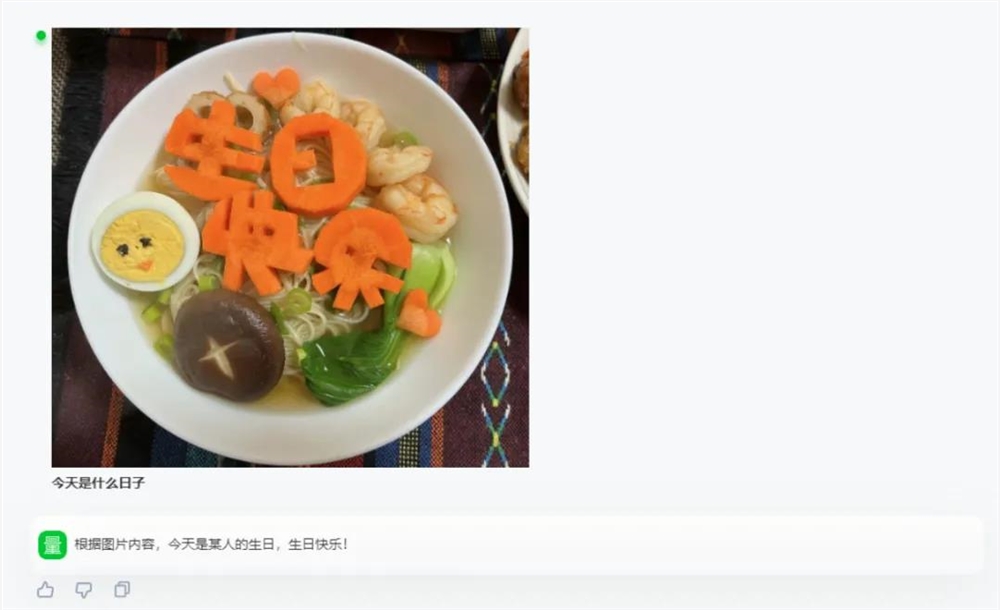
还能充当生活助手,准确识别食物并提供卡热量参考:

提供养宠物建议:

商量看得如此精准主要是因为其底层的商汤多模态大模型图文感知能力已达到全球领先水平 —— 在多模态大模型权威综合基准测试 MMBench 中综合得分排名首位,在多个知名多模态榜单 MathVista、AI2D、ChartQA、TextVQA、DocVQA、MMMU 成绩也相当亮眼。
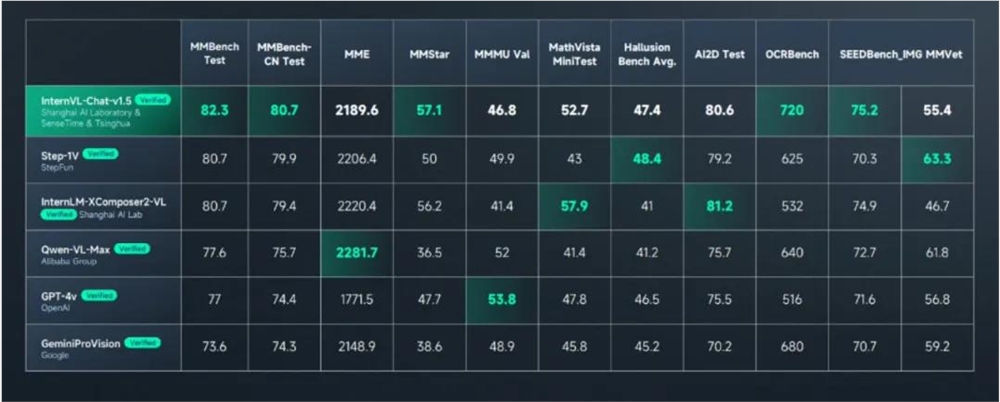
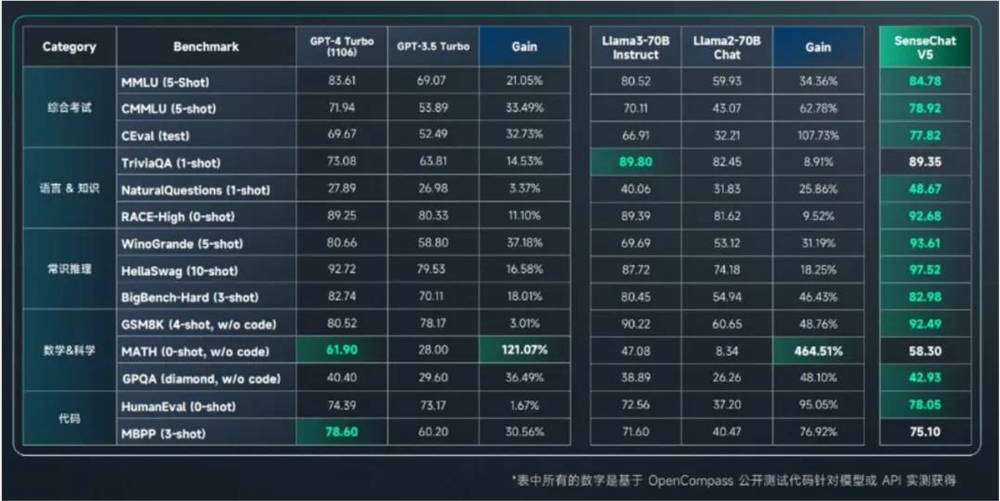
今天最新升级的 “日日新 SenseNova5.0” 也在主流客观评测上取得多项 SOTA,在主流客观评测上达到或超越 GPT-4Turbo,数学推理、代码编程、语言理解等多个维度取得重大突破。
大模型性能边界在哪里?
商汤:尺度定律是人工智能发展最基本的法则
随着模型规模的不断扩大和复杂度的增加,人们自然会产生一个问题:大模型的性能到底有多强?
在这个问题上,尺度定律(Scaling Law)被认为是一个关键性的原理,即伴随模型规模的增大,模型的性能也会随之提升,每次大模型训练的结果都高度可预测。
商汤也以此作为大模型研发的基本法则,不断探究大模型性能的边界。
然而,数据和算力依然是大模型在尺度定律探索道路上的瓶颈,商汤也对此一直在突破。
对此,商汤不断突破数据和算力的边界。
比如,在此次 “日日新5.0” 的升级中,商汤扩展了超过10TB tokens 的预训练中英文数据,规模化构建高质量数据,解决大模型训练的数据瓶颈。在算力方面,商汤前瞻布局的算力基础设施 SenseCore 商汤大装置,更通过算力硬件系统及算法设计的联合设计优化,为大模型的创新提供超高算力效率。
高质量数据和高效率算力的支持,为商汤践行尺度定律,奠定了长期基础。
在此之上,商汤还探索出了大模型能力的 KRE 三层架构,具象化展现了大模型能力边界的定义。
其中,K 是指知识(Knowledge),即世界知识的全面灌注;R 是指推理(Reasoning),即理性思维的质变提升;E 是指执行(Execution),即世界内容的互动变革。
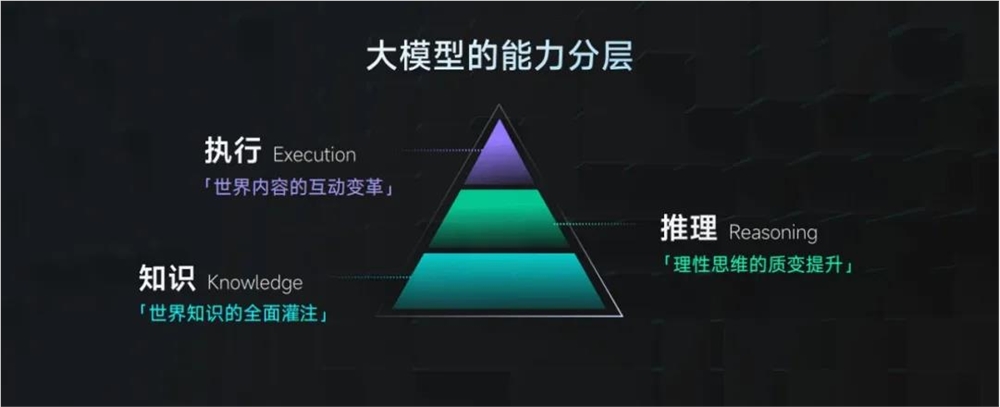
三层之间互有依赖,但又相对独立。最终的目标,是建立大模型对世界的强大学习、理解和交互能力。
大模型在学习这个世界,也在创造一个 AI Native 的世界,无论是大模型原生小游戏,还是功能越来越全的大模型对话,都在展现世界内容的互动变革,随着尺度规律的不断发展,下一步会怎样?
在这次技术交流日上,商汤最后放出了一段文生视频,一起来看看。
更新于:7个月前