
AI也可以生成延时视频了 MagicTime输入文本即可生成植物生长视频
近期,一个名为MagicTime的新模型引起了业界的广泛关注。这个模型专注于生成变形时间延迟视频,基于DiT(Deformable Image Transformer)的架构,解决了现有文本到视频(T2V)生成模型未能充分编码现实世界物理知识的问题。
项目演示:https://top.aibase.com/tool/magictime
代码:https://github.com/PKU-YuanGroup/MagicTime
在传统的T2V生成中,生成的视频往往具有有限的动作和变化,这是由于这些模型无法准确反应现实世界的物理规律。为了克服这一限制,MagicTime引入了变形时间延迟视频的概念,旨在提高视频生成的质量和真实性。
MagicTime的主要功能包括:
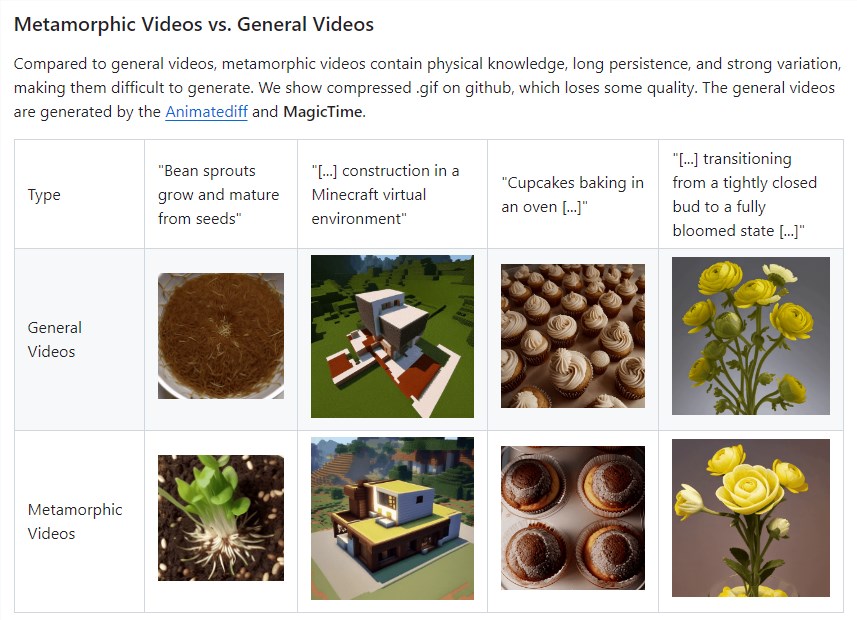
变形时间延迟视频生成:MagicTime专注于生成包含物理知识、长期持续性和强烈变化的变形视频,这些视频比常规视频包含更丰富的物理知识和变形过程。
MagicAdapter方案:通过设计MagicAdapter方案,MagicTime能够解耦空间和训练时间,从变形视频中编码更多的物理知识,并转换预训练的T2V模型以生成变形视频。
动态提取帧策略:引入动态帧提取来策略适应变化范围更广的变形时间延迟视频,更好地体现物理知识。
Magic Text-Encoder:改进了对变形视频提示的理解,提高了文本到视频生成的准确性和质量。
ChronoMagic数据集:创建专门的时间延迟视频文本数据集ChronoMagic,为解锁变形视频生成能力提供支持。
MagicTime的目标是通过生成高质量和动态的变形视频,证明其对生成时间延迟视频的依据性和有效性,为构建物理世界的现变形模拟器开辟了一条希望的道路。
此外,MagicTime还计划将额外的变形景观时间延迟视频集成到相同的注释框架中,查找ChronoMagic-Landscape数据集,然后使用该数据集Open-Sora-Plan v1.0.0,获得MagicTime-DiT模型。
更新于:7个月前