
亚马逊发布其有史以来最大的文本转语音模型 BASE TTS
划重点:
⭐️ 亚马逊 AGI 团队发布了有史以来最大的文本转语音模型,具有最多的参数和最大的训练数据集。
⭐️ 新模型名为 BASE TTS,拥有980亿参数,使用了10万小时的录音数据进行训练,主要是英语。
⭐️ 该团队计划将 BASE TTS 用作学习应用,以改进文本转语音应用的人类声音质量。
亚马逊 AGI 的人工智能研究团队宣布开发了他们所描述的有史以来最大的文本转语音模型。所谓最大,是指拥有最多参数并使用最大训练数据集。他们在 arXiv 预印服务器上发布了一篇论文,描述了该模型的开发和训练过程。
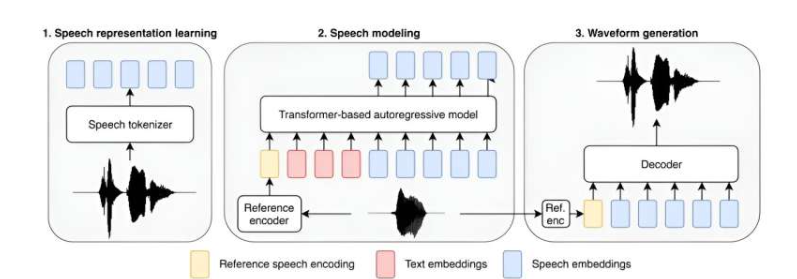
与 ChatGPT 等大型语言模型(LLMs)因其人类化的智能回答问题和创建高水平文档的能力而备受关注不同,人工智能正在逐步应用于其他主流应用。在这一新尝试中,研究人员试图通过增加模型参数的数量和扩充训练基础来改进文本转语音应用的能力。
这一新模型被称为 Big Adaptive Streamable TTS with Emergent abilities(简称为 BASE TTS),拥有98亿参数,并使用了10万小时的录音数据进行训练,其中大部分是英语。该团队还为其提供了其他语言中已知短语的口语单词和短语示例,以使模型在遇到这些短语时能够正确发音,比如 “au contraire” 或 “adios, amigo”。
亚马逊团队还在较小的数据集上对模型进行了测试,希望了解模型何时会出现所谓的新兴特性,即人工智能应用,无论是 LLM 还是文本转语音应用,突然似乎突破到更高层次的智能。他们发现,对于他们的应用程序来说,新兴特性出现在拥有1.5亿参数时。
他们还指出,这种飞跃涉及一系列语言属性,例如使用复合名词,表达情感,使用外语词汇,应用语音附加语和标点,以及在句子中将重点放在正确的单词上提出问题。
该团队表示,他们不会向公众发布 BASE TTS,因为他们担心它可能被不道德地使用,而是计划将其用作学习应用。他们希望应用他们迄今为止所学到的知识,以改进文本转语音应用程序的人类声音质量。
论文网址:https://dx.doi.org/10.48550/arxiv.2402.08093
更新于:9个月前