
大模型开山鼻祖!InstructGPT发布两周年了
今天是InstructGPT发布两周年的纪念日,它是现代大语言模型的开山鼻祖。Jim Fan介绍了InstructGPT的重要性并且说了几条关于InstructGPT非常有意思的点。还展示了InstructGPT中非常经典的三步LLM训练方法的图片,我也顺便让GPT-4解释了一下也顺便放在下面。
InstructGPT 开创了一个经典的模型训练方法:先进行预训练,然后是监督式微调,最后是基于强化学习的人类反馈(Reinforcement Learning from Human Feedback, RLHF)。这个策略至今仍被广泛采用,虽然有些许变化,比如 DPO 策略。InstructGPT 可能是 OpenAI 最后一次详细介绍他们如何训练尖端模型的论文。回顾这两年,Jim Fan认为它标志着大语言模型从学术研究(GPT-3)走向实际应用(ChatGPT)的关键转折点。
InstructGPT 并非 RLHF 的发明者。实际上,它的博客链接指向了 OpenAI 团队在2017年完成的最早的 RLHF 研究。RLHF 的初衷是解决模拟机器人领域中难以定义的任务。它通过要求人类注释者给出900个简单的是非选择,帮助一个名为“跳跃机器人”的机器人在模拟环境中学会了后空翻。
InstructGPT 在2022年的 NeurIPS 会议上亮相,地点是新奥尔良。当时Jim Fan正在会上展示他的项目 MineDojo,看到 OpenAI 的展示非常惊喜。这些模型有三种规模:1.3B、6B 和175B。与老式的、需要复杂提示的 GPT-3-175B 相比,标注者更加青睐 Instruct-1.3B。而且,Microsoft Phi-1,作为众所周知的小型优秀语言模型之一,也是1.3B。
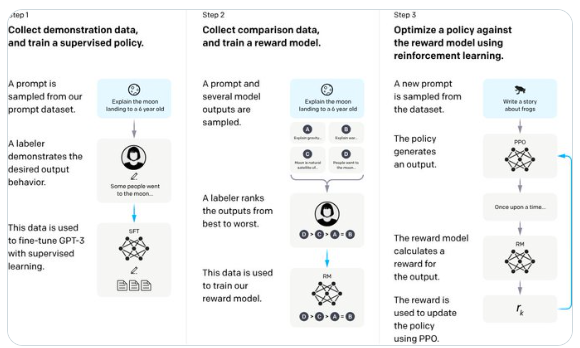
InstructGPT 在展示研究方面堪称典范。它的三步骤图解清晰易懂,成为 AI 领域最具标志性的视觉之一。的引言部分直奔主题,用粗体突出了八个主要观点。对于模型局限性和偏见问题的讨论,也是实事求是和坦诚的。
InstructGPT模型三步训练意图介绍:
第1步:收集示范数据,并训练一个监督策略。从我们的提示数据集中抽取一个提示,例如“向一个6岁的孩子解释月球登陆”。标注者提供期的输出行为,例如“一些人去了月球”。这些数据被用来通过监督学习细调GPT-3模型。
第2步:收集比较数据,并训练一个奖励模型。抽取一个提示和几个模输出样本,例如同样是“向一个6岁的孩子解释月球登陆”。标注者会对这些输出进行排名,从最好到最差。这些数据被用来训练我们的奖励模型。
第3:使用强化学习对奖励模型优化策略。从数据集中抽取一个新的提示,例如“写一个关于青蛙的故事”。策略生成一个输出,比如开始写“从前有一次…”。励模型计算一个奖励值给这个输出。这个奖励值被用来通过PPO(比例策略优化)更新策略。整个过程展示了从收集数据到通过人类标注者的反馈来训练和优化人工智能模型的步骤。这种方法结合了监督学习和强化学习来改进模型的性能。
更新于:9个月前