
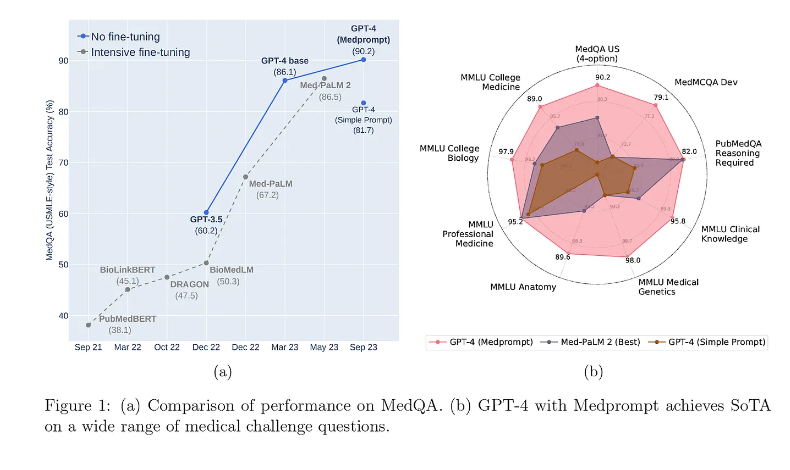
GPT-4在医学问题上击败了专业调优的 MedPaLM 2 模型
在研究中,微软的研究人员展示了GPT-4在医学知识测试中的卓越表现,特别是当结合先进的提示工程技术时,其性能超过了专业调整的MedPaLM2。
研究结果显示,相较于费时费力的调优和模型训练,将更有效的提示工程应用于主流通用模型可能是实现更准确结果的更好途径。
Medprompt方法采用了多种提示工程技术,包括GPT-4生成的思维链推理和生成多个单独评分的回答,然后将最高分的答案返回给用户。尽管这种方法会增加推理的成本,因为生成了更多的标记,但结果表明,将领先的通用模型(如GPT-4)与高级提示工程技术相结合,以评估最新性能的标准,可能是值得考虑的。
研究人员使用MultiMedQA数据集进行了一系列测试,包括MedQA、MedMCQA、PubMedQA和MMLU等。虽然测试仍然是多项选择答案,但研究强调,这些结果可能在真实世界的自由文本回答中有所不同。Medprompt方法结合了从零到5个提示技术,展现出了强大的性能。
值得注意的是,研究强调GPT-4生成的思维链推理相对于专家手工制作的Med-PaLM2提示更为优越,因为它提供了更精细的逐步推理逻辑。然而,研究也指出,这一结论是特定于GPT-4的,而不适用于其他通用基础模型。
对于企业部署领域专业生成性AI解决方案的实际操作,研究建议在转向调优或定制模型训练之前,应考虑如何通过提示工程技术提高模型准确性。此外,高级提示工程技术,如模型生成的提示和集成评分,可能进一步改善调优或定制模型。
总的来说,研究的重要性在于发现通过提示工程技术可能实现与调优相媲美的性能,从而加速上市时间并降低成本。然而,研究也指出,企业选择使用通用基础模型还受到数据隐私、数据和应用程序安全性、成本和竞争优势等多方面因素的影响。
研究者强调,改进大语言模型输出的准确性是当前讨论的中心主题,而通过提示工程技术可能是最简单、成本最低的方法之一。
研究结果可能对领域定制模型的开发产生重大影响,因为如果通过更有效的提示工程技术可以获得相同或更好的性能,那么传统的调优方法可能会受到挑战。然而,选择使用通用基础模型仍然涉及到多方面的考虑,包括数据隐私、安全性、成本和竞争优势等因素。
更新于:2023-12-04 13:04