
GPT-4作弊被抓,吉娃娃or松饼打乱顺序就出错,LeCun:警惕在训练集上测试
GPT-4解决网络名梗“吉娃娃or蓝莓松饼”,一度惊艳无数人。
然鹅,现在它被指出“作弊”了!

全用原题中出现的图,只是打乱顺序和排列方式。
结果,最新版全模式合一的GPT-4不但数错图片数量,原来能正确识别的吉娃娃也识别出错了。
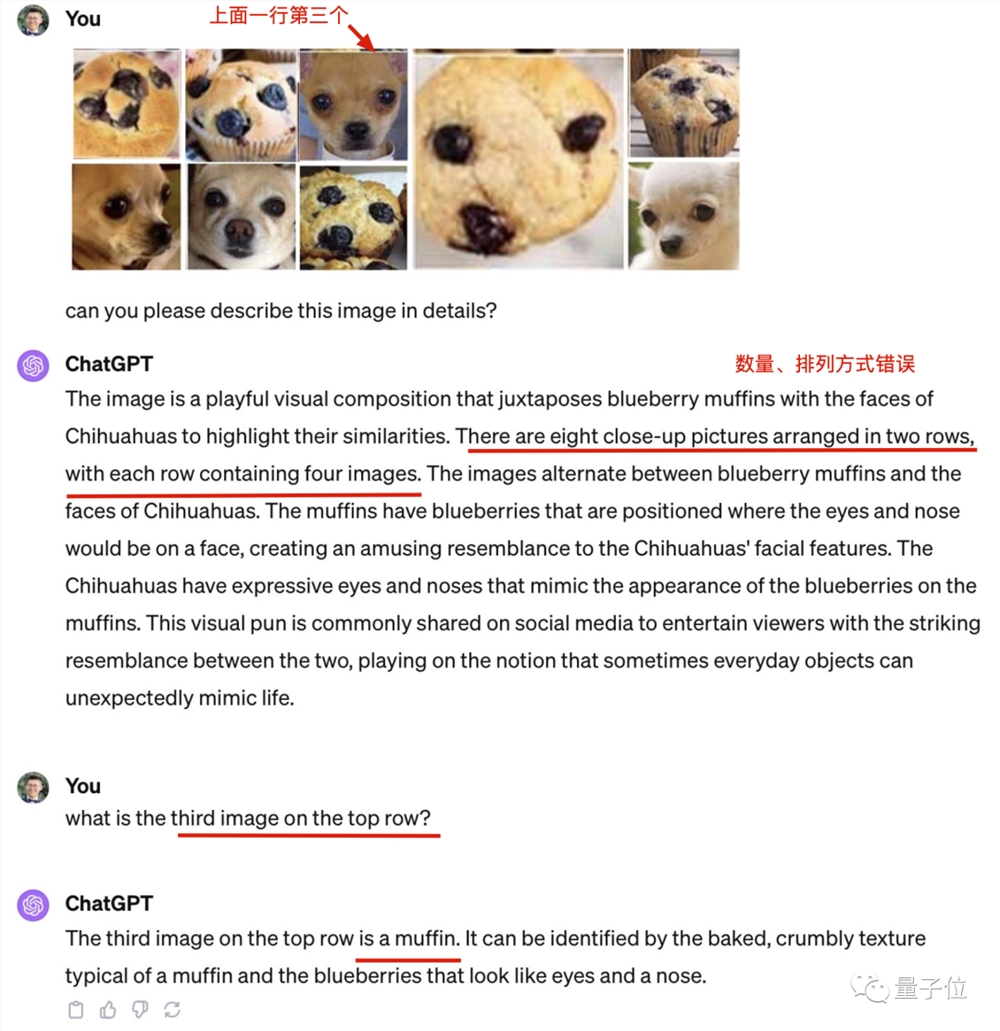
那么为什么GPT-4在原图上表现的这么好呢?
搞这项测试的UCSC助理教授Xin Eric Wang猜测,原图在互联网上太流行,以至于GPT-4在训练时多次见过原答案,还给背了下来。
图灵奖三巨头中的LeCun也关注此事,并表示:
警惕在训练集上测试。

泰迪和炸鸡也无法区分
原图究竟有多流行呢,不但是网络名梗,甚至在计算机视觉领域也成了经典问题,并多次出现在相关论文研究中。

那么抛开原图的影响,GPT-4能力究竟局限在哪个环节?许多网友都给出了自己的测试方案。
为了排除排列方式太复杂是否有影响,有人修改成简单3x3排列也认错很多。


有人把其中一些图拆出来单独发给GPT-4,得到了5/5的正确率。
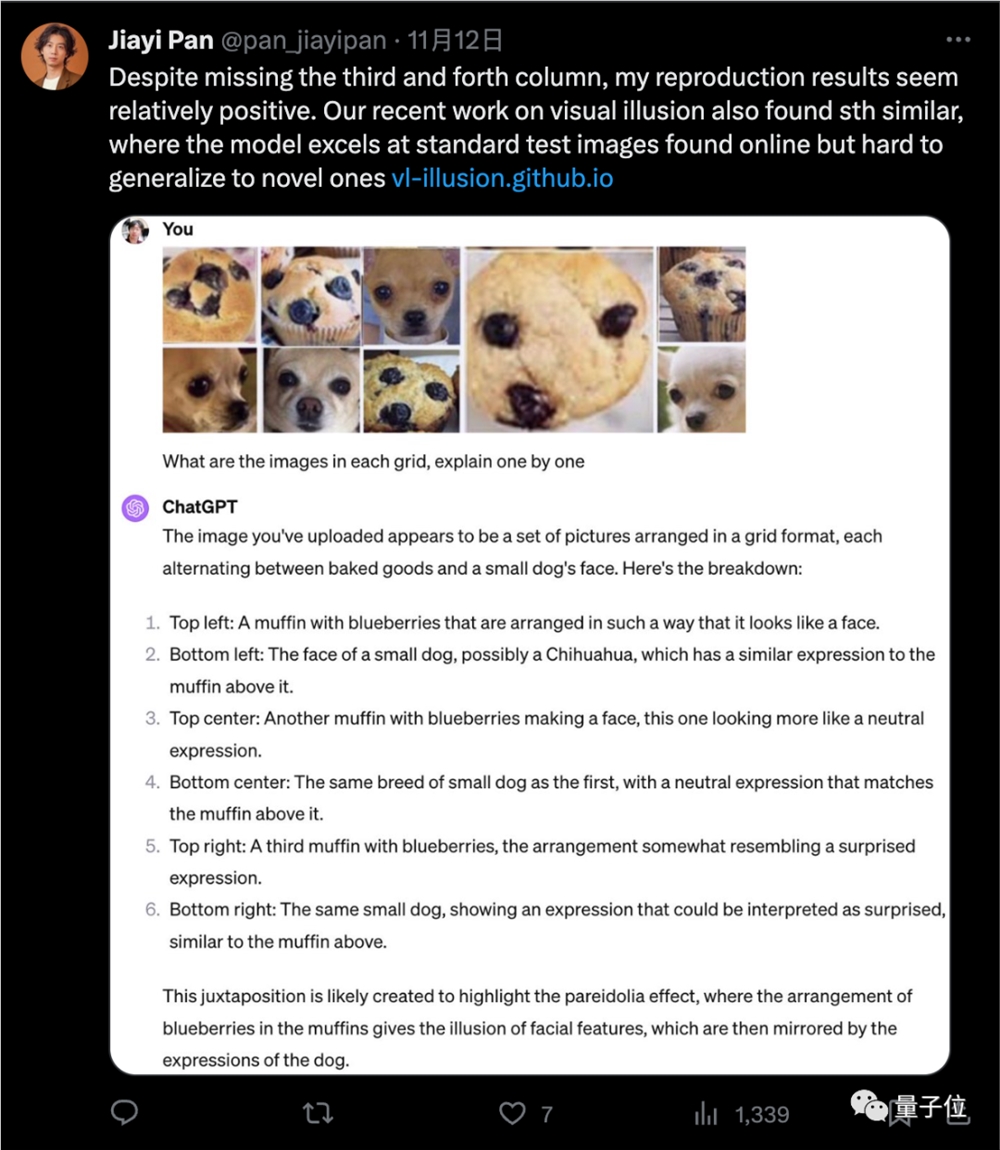
但Xin Eric Wang认为,把这些容易混淆的图像放在一起正是这个挑战的重点。

终于,有人同时用上了让AI“深呼吸”和“一步一步地想”两大咒语,得到了正确结果。

但GPT-4在回答中的用词“这是视觉双关或著名梗图的一个例子”,也暴露了原图确实可能存在于训练数据里。

最后也有人测试了经常一起出现的“泰迪or炸鸡”测试,发现GPT-4也不能很好分辨。

但是这个“蓝莓or巧克力豆”就实在有点过分了……

视觉幻觉成热门方向
大模型“胡说八道”在学术界被称为幻觉问题,多模态大模型的视觉幻觉问题,已经成了最近研究的热门方向。
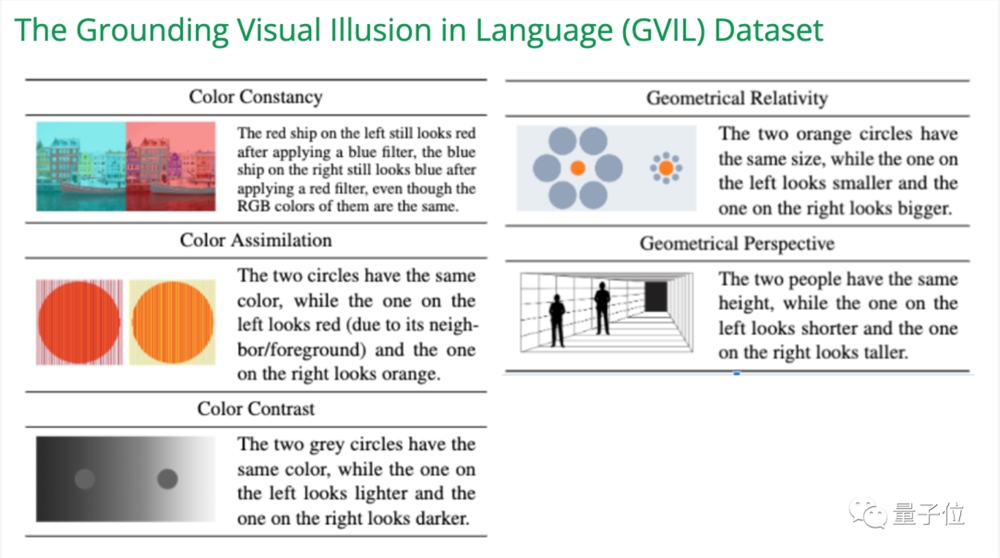
在EMNLP2023一篇研究中,构建了GVIL数据集,包含1600个数据点,系统性的评估视觉幻觉问题。

研究发现,规模更大的模型更容易受到错觉的影响,而且更接近人类感知。
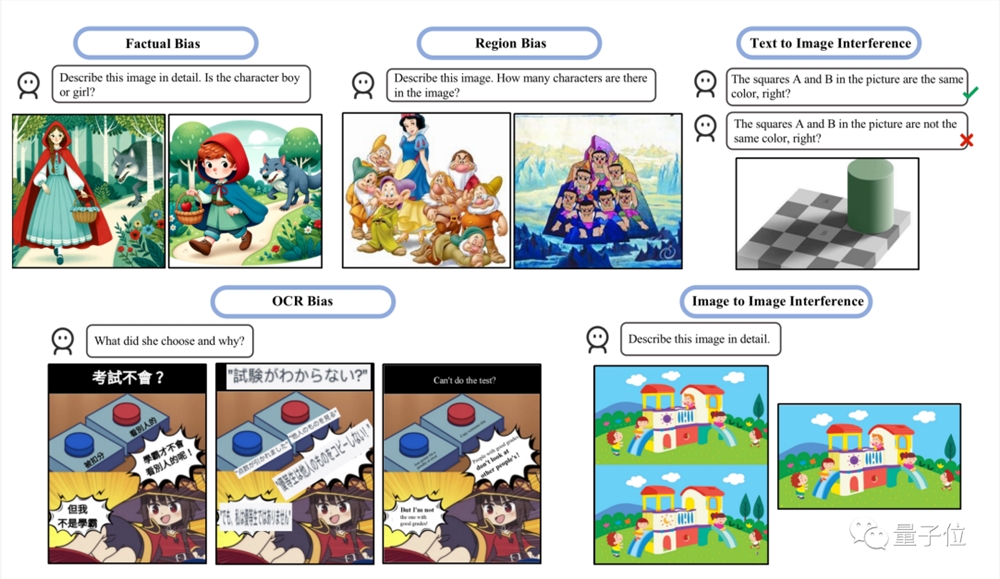
另一篇刚出炉的研究则重点评估了两种幻觉类型:偏差和干扰。

偏差指模型倾向于产生某些类型的响应,可能是由于训练数据的不平衡造成的。
干扰则是可能因文本提示的措辞方式或输入图像的呈现方式造成去别的场景。
研究中指出GPT-4V一起解释多个图像时经常会困惑,单独发送图像时表现更好,符合“吉娃娃or松饼”测试中的观察结果。

流行的缓解措施,如自我纠正和思维链提示并不能有效解决这些问题,并测试了LLaVA和Bard等多模态模型存在相似的问题。
另外研究还发现,GPT-4V更擅长解释西方文化背景的图像或带有英文文字的图像。
比如GPT-4V能正确数出七个小矮人+白雪公主,却把七个葫芦娃数成了10个。

参考链接:
[1]https://twitter.com/xwang_lk/status/1723389615254774122
[2]https://arxiv.org/abs/2311.00047
[3]https://arxiv.org/abs/2311.03287
更新于:2023-11-14 12:12