
PyTorch团队重写Meta“分割一切”模型 性能提速8倍
要点:
PyTorch团队通过对Meta的「分割一切」(SAM)模型进行重写,使其在原始实现的基础上提速8倍,同时保持准确率。
优化方法包括采用PyTorch原生特性如Torch.compile、GPU量化、SDPA等,以及使用半精度(bfloat16)、自定义Triton内核、Nested Tensor、量化、半结构化稀疏性等操作。
文章介绍了SAM模型的性能分析、瓶颈识别,以及采用Bfloat16、Torch.compile等优化措施,最终将GPU同步和性能提升结合,使SAM性能提高了3倍。
生成式AI领域的迅猛发展带来了训练和推理速度的压力,特别是在使用PyTorch的情况下。为了解决这一难题,PyTorch团队通过优化Meta的「分割一切」模型,成功地提升了推理速度。论文从浅入深地介绍了优化的过程和所采用的技术。
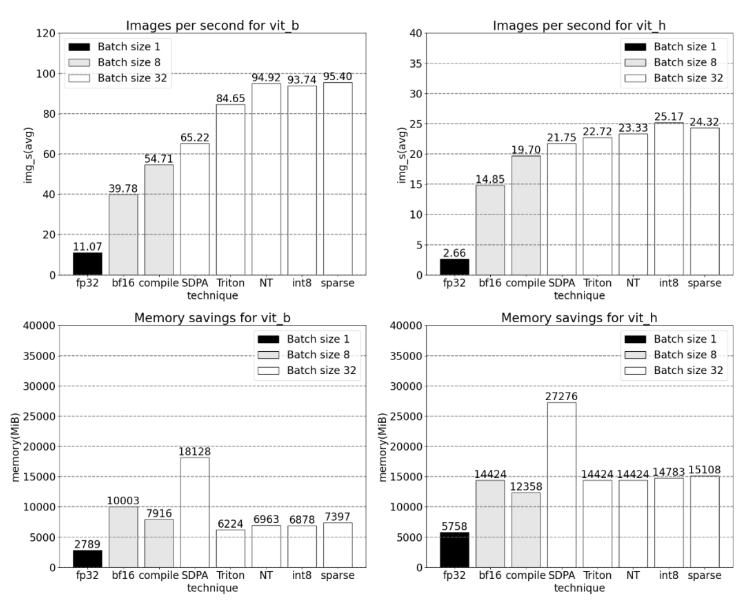
首先,通过Bfloat16半精度和优化GPU同步,矩阵乘法等操作,成功地减少了SAM模型的计算时间,提高了性能。其次,PyTorch引入了新的功能,如Torch.compile模型编译器,GPU量化等,通过减少内存开销和增加吞吐量,进一步加速了生成式AI模型。

论文还深入介绍了SDPA(Scaled Dot Product Attention)技术,这是一种内存高效的注意力实现方式,结合Torch.compile和其他优化手段,有效加快了GPU上的注意力计算。此外,通过使用Nested Tensor将不同大小的数据批处理到单个张量中,以及使用Triton自定义操作,成功地集成了各种功能到PyTorch的组件中,进一步提高了模型的整体性能。
对SAM模型的重写以及通过剪枝等方式解决矩阵乘法作为瓶颈的问题。通过这些优化,SAM模型的性能得到了显著提升,而不牺牲准确率。总体而言,PyTorch团队的努力通过技术手段的优化成功提高了生成式AI模型的训练和推理速度,为AI领域的发展贡献了重要的方法和工具。
更新于:2023-11-22 13:19