别人家的夏天和那不会结果的爱
夏日来到最后一个节气,江浙沪也陆续出梅,如此美好的盛夏,有何理由不做一场不结果的恋爱。

在看官们开始颠鸾倒凤前,不如一同先回味一下这场在笔者看来近年最甜美的盛夏爱情故事,权当温床了。

电影《请以你的名字呼唤我》改编自犹太作家安德烈·艾席蒙的同名纯爱小说,由改编大佬詹姆斯·伊沃里担任编剧,意大利导演卢卡·瓜达尼诺执导,加上好莱坞当红鲜肉“甜茶”蒂莫西·柴勒梅德和出演过《社交网络》的艾米·汉莫分别饰演两位主角,本片从定项开始就备受关注,在18年第90届奥斯卡上拿到除导演奖外的四项大奖提名,并最终斩获最佳改编剧本奖。
内容上,影片和原著差距不大。

讲述在一个夏天的意大利北部小城,17岁的Elio遇见了父亲招来游学的美国学生Oliver,两人开始彼此吸引、试探和热恋,在这个连猫狗都会彼此相爱的盛夏美景里留下了人生最珍贵的回忆。
硬要找有什么明显不同的话,那就是电影将书中大量的心理描写通过演员表演外在表现了出来。

这就不得不说,继《伯德小姐》后,甜茶的演技在这一部中迎来了大爆发,他在这部电影中的每一个阶段甚至每一秒的状态都特别的准确,不断牵动着观众和他一起体验其内在的情感高潮。
除了惊艳的演技外,这也得益于编剧高超的改编技巧,奥斯卡的改编剧本奖可谓实至名归。

而导演则自愿将自己的功力隐藏在了原著、剧本和表演的耀眼光芒下,这倒不是贬低,因为如此纯粹的情感就得配上干净的画面和干净的剧情,在这座小城中,少即是多。
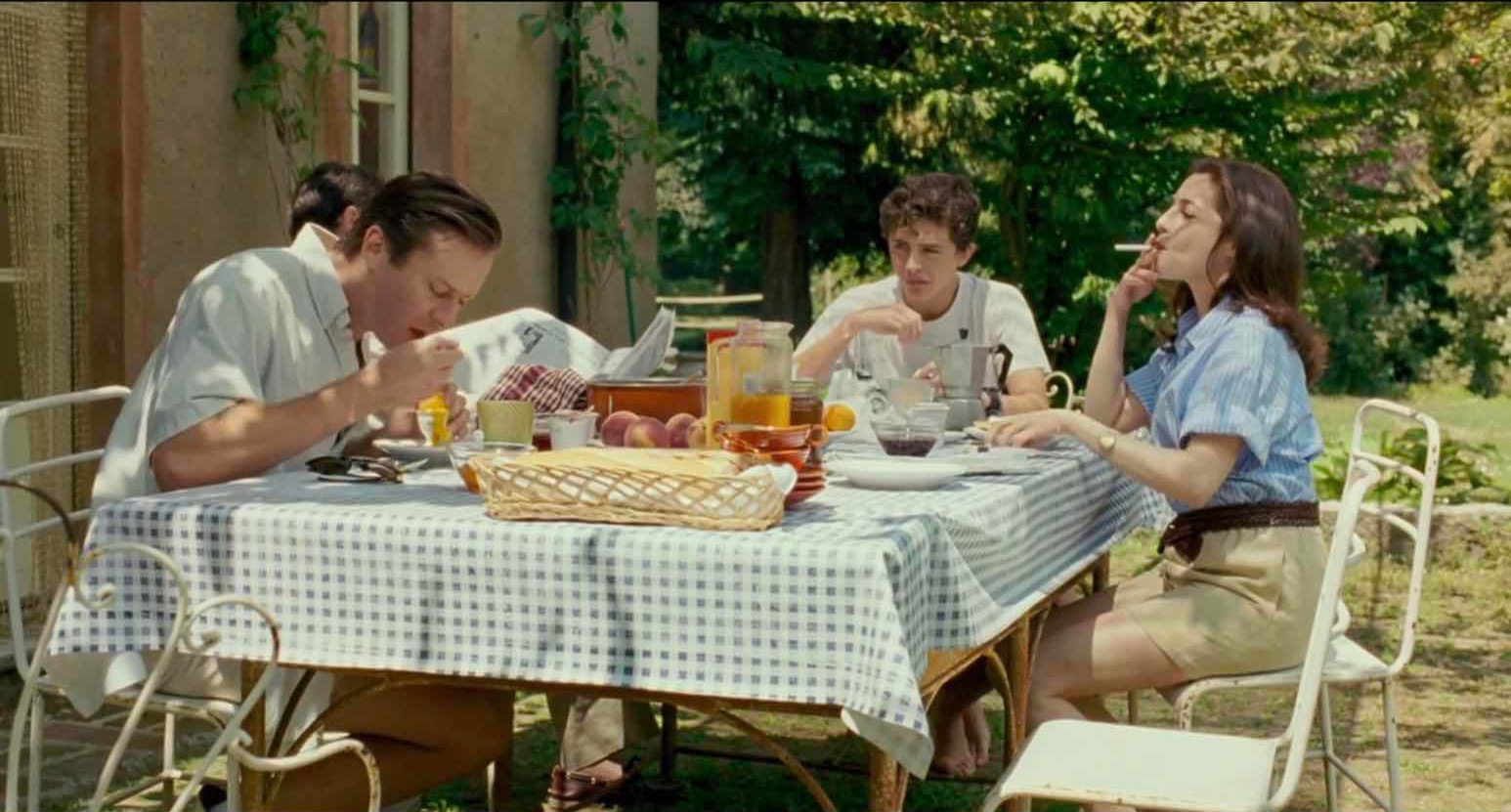
当Oliver第一次和Elio一家共进早餐时,同样是半熟的鸡蛋,Oliver 用勺舀得一桌汤汤水水,Elio则是含蓄优雅地慢慢吸吮。

这样的对比放在两人的情感上恰好相反,Elio反而成了更笨拙和心急的那个,Oliver则成熟老练。
Oliver说自己很明白如果自己再吃第二颗蛋就会一直吃到停不下来。
他对Elio家鸡蛋的理念就像他对待Elio感情的态度。

一个想要靠近又不敢确定,一个想要推开而又不舍,他们起初就这样疯狂试探。如此漫长却又动人的前戏可能就是让每一个心思细腻的观众都欲罢不能的原因吧。

虽然Elio看似是那个更主动也更具攻击性的,但Oliver才是这段情感中掌握绝对主动权的一方。撩人的是他,拒绝的是他,最后离开的还是他。
导演曾在解释片名时说:在爱情中,当你用自己的名字叫对方时,就代表你已经完完全全的投降了。

Elio在Oliver的眼中就像那颗蛋,水多但不成形。而恰恰也是这样生猛和原始的激情,让Oliver最终缴械投降。
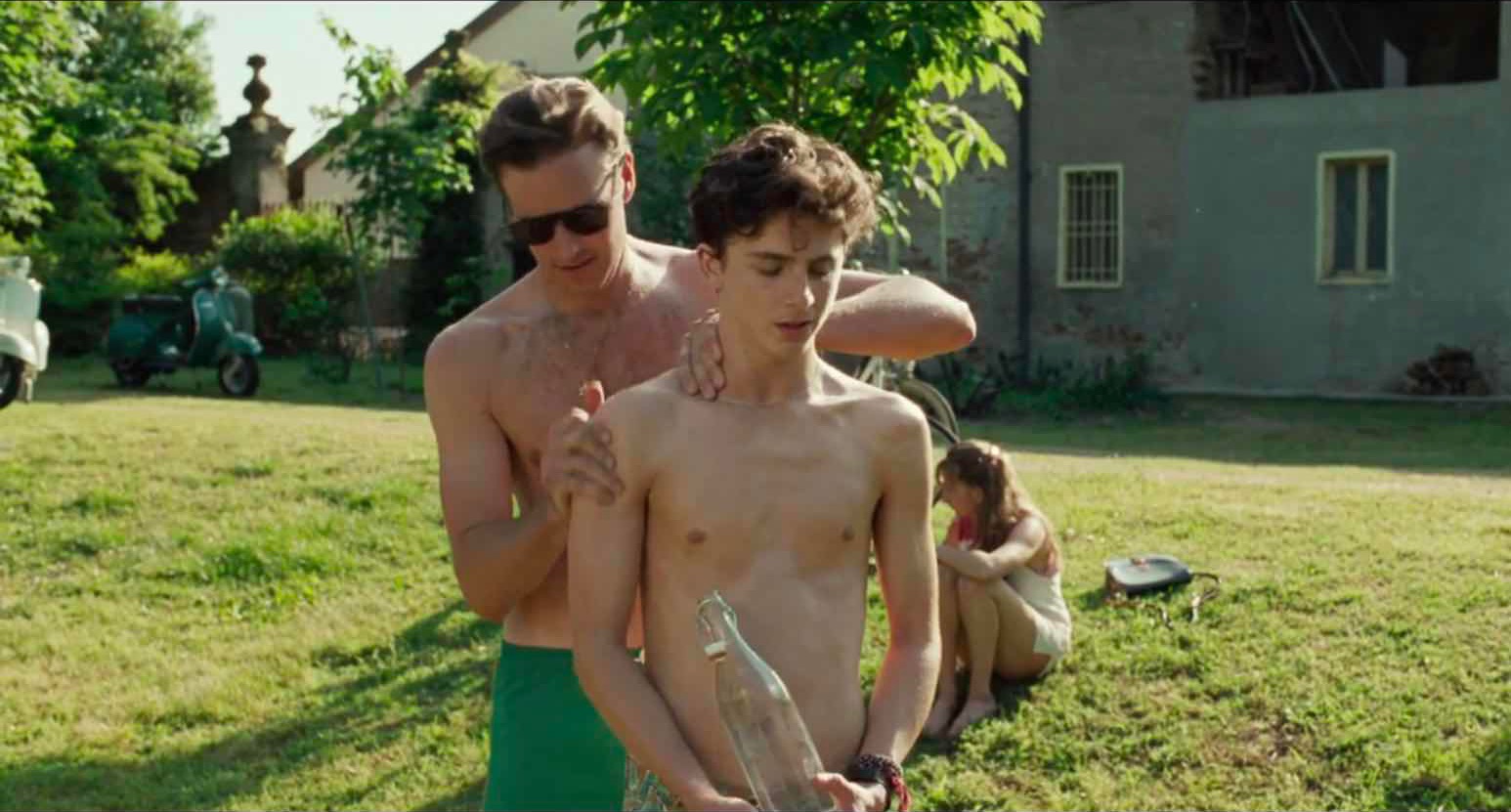
整个影片两个多小时,几乎没有任何来自外部的干扰。无论是艺术、政治还是信仰,都没有对两位主角形成干扰,它们在我看来只是点缀影片文艺气氛的花招。故事的进程全由Elio和Oliver间的情感所牵动,如果范围再缩小一些,懵懂却热烈的Elio就是全片的中心。

Elio在经历了女性、双手、男性和蜜桃之后最终确认了自己的归属。
但这个好不容易找到的归属太过热烈,激情伴随的是流血和呕吐,并最终以笑容和泪水收场。

从这点看,本片的主线并不在Elio和Oliver间的感情上,而更多的应该是聚焦于Elio自身青春状态的成长。
虽然Elio父亲片尾那段长篇大论看似有给Elio性向找补的嫌疑,但却也不失为对全片的一次完整总结。

“年纪越大我们对一段新的感情能付出的也就越少。满腔热烈的爱意和奋不顾身的勇气,是一段刻骨铭心的爱情,也是我们曾经年轻的证据。”

试问如果是当下正处盛夏的我们,面对这样一场注定不会结果的爱情,是否还会像Elio一样奋不顾身,给生命留下青春的印记?
说到Elio的父亲(迈克尔·斯图巴 饰),他是这部影片中除两位男主外给笔者留下最深印象的角色。

睿智幽默还开得一手好车,他的确定出演使我对本片的续集充满了期待。

片中的意大利仲夏太过美好,怎么看怎么不像自己家,而这样干净细腻的纯爱似乎也只有在这样抽离了现实的世外桃源里才会发生。相比甜茶那甜到不行的初尝云雨,更能让刚走出梅雨就步入雾霾的油腻笔者产生共情的,反而是这位历经风雨的老司机。暗中观察且深藏不露。
相关资讯
《妹妹》:《鬼庄园》那不叫扑街,这才是!
隔壁《鬼庄园》(《鬼入侵》第二季)刚刚完结,ITV出品的这部MINI剧《妹妹》就播出了,不知对它是幸还是不幸。《鬼入侵》系列把鬼片外壳、恐怖梗和惊悚氛围玩得非常高级,短期内恐怕不会出现能超越第一季的同类型影视作品。由于第一季光芒太盛,第二季虽然有扑街嫌疑,但看到最后..
《玫瑰的故事》结局:傅家明为什么至死不愿娶玫瑰?因那不是爱情
本文写的原著,和电视剧有所出入。原著中傅家明至死都不愿娶玫瑰,而玫瑰抛弃了女儿也要嫁给傅家明。这段感情让很多人感动,可是我却觉得有些讽刺和可笑。在书中玫瑰她此生最爱的是傅家明,在剧中傅家明也被塑造成了玫瑰的“灵魂伴侣”。可是我在书中看这段“生死爱情”的时候,我..