
Deepmind新AI算法仅用两个小时学习了26个游戏 与人类相当
日前,Deepmind的一个名为 Bigger, Better, Faster 的 AI 算法,在只用了两小时的时间内掌握了26个 Atari 游戏,与人类效率水平相当。
强化学习是谷歌深度学习中心研究的核心领域之一,它可能有朝一日用 AI 解决许多现实世界的问题。然而,一个大问题是可能会非常低效:强化学习算法需要大量的训练数据和大量的计算能力。在他们的最新研究中,谷歌深度学习中心和米拉大学和蒙特利尔大学的研究人员展示了另一种可行的方法。
Bigger, Better, Faster的模型(简称BBF)在Atari基准测试中平均表现超出了人类的表现水平。这并不是新鲜事,其他强化学习算法也曾在 Atari 游戏中击败了人类。
然而,BBF模型只需要两个小时的游戏时间,这与人类在基准测试中使用的实践时间是相同的。因此,这个不需要预先训练模型的算法达到了人类学习的效率,并且需要的计算能力比旧方法少得多。无模型代理直接从与游戏世界的交互中获得奖励和惩罚的信息,并学习到最佳的策略。
该团队通过使用更大的神经网络、自我监控训练方法和其他方法来提高效率。例如,BBF可以在单个Nvidia A100GPU上进行训练,而其他方法需要更多的计算能力。
虽然还有29个常用于强化学习的游戏尚待测试,但研究团队指出,BBF 还没有能够在所有基准测试游戏中超过人类的表现水平。然而,将 BFF 与其他模型在55个游戏中进行比较,表明这种高效算法在55个游戏中大致与使用500倍更多数据的系统持平。
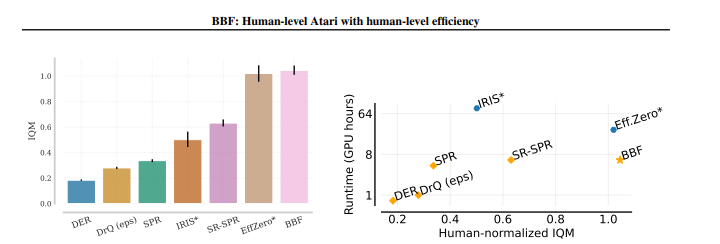
该团队认为,这还表明 Atari 基准测试仍然是强化学习的好的基准测试,这使得该研究可以为小型研究团队提供资金支持。
过去的高效强化学习算法对扩展方面也显示出了弱点,而 BFF 没有限制,并且继续能够通过更多的训练数据获得更高的性能。
该团队总结道:“总体来说,我们希望我们的工作能够激励其他研究人员继续推进深度强化学习的样本效率前沿,以最终达到人类水平的效率表现在所有任务中。”
更有效率的强化学习算法可能会重新确立目前由自我监督模型主导的 AI 技术的局面。
BBF算法相关论文:https://arxiv.org/pdf/2305.19452.pdf
更新于:2023-06-20 13:28