
超9000颗星,优于GPT-4V!国内开源多模态大模型
国内著名开源社区OpenBMB发布了最新开源多模态大模型——MiniCPM-V2.6。
据悉,MiniCPM-V2.6一共有80亿参数,在单图像、多图像和视频理解方面超越了GPT-4V;在单图像理解方面优于GPT-4o mini、Gemini1.5Pro 和 Claude3.5Sonnet。
值得一提的是,MiniCPM-V2.6显著减少了模型的内存占用并提高了推理效率,首次支持iPad等端侧设备进行实时视频理解的模型。
开源地址:https://github.com/OpenBMB/MiniCPM-V
在线demo:https://huggingface.co/spaces/openbmb/MiniCPM-V-2_6

MiniCPM-V2.6是基于SigLip-400M和阿里的Qwen2-7B模型开发而成,相比V2.5性能进行了大幅度更新,并引入了多图像和视频理解的特色功能。
性能超强:在最新版本的OpenCompass上平均得分达到65.2,在8个流行基准测试中表现很好。仅用80亿参数就超越了GPT -4o mini、GPT -4V、Gemini1.5Pro和Claude3.5Sonnet等知名多模态大模型在单图像理解方面的性能。
多图像理解和上下文学习能力:能够对多图像进行对话和推理,在Mantis - Eval、BLINK、Mathverse mv和Sciverse mv等多图像基准测试中达到了领先水平,同时展示出了卓越的上下文学习能力。
视频理解能力优秀:可以接受视频输入,对视频进行对话并为时空信息提供密集的字幕。在Video - MME测试中,无论是否有字幕的情况下,都优于GPT -4V、Claude3.5Sonnet和LLaVA - NEXT - Video -34B。
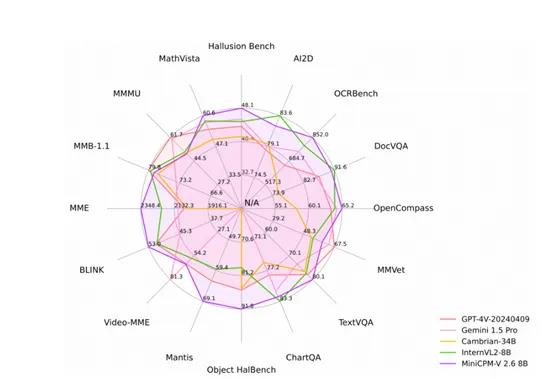
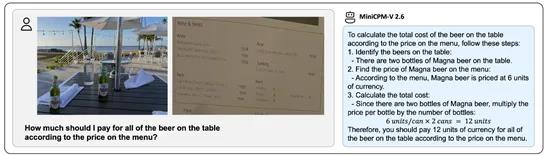
特色OCR识别能力:该版本在OCR任务上展现了更强的能力,能够更准确地识别和转录图像中的文字,例如,可以处理任何宽高比且高达180万像素(如1344x1344)的图像,在OCRBench上达到了领先水平,超越了GPT -4o、GPT -4V和Gemini1.5Pro等专有模型。
安全可靠:在可信行为方面,MiniCPM-V2.6基于最新的RLAIF - V和VisCPM技术,减少了幻觉的产生提高了模型的可信度,在Object HalBench上的幻觉率显著低于GPT -4o和GPT -4V。
多语言支持:MiniCPM-V2.6支持英语、中文、德语、法语、意大利语、韩语等多种语言,增加了对更多语种的识别和生成能力,帮助开发者开发不同语言的应用。
卓越的推理效率:具有非常棒的token密度,例如,处理180万像素的图像时仅产生640个token,这比大多数模型少75%,极大提升了推理效率、首token延迟、内存使用和功耗,使其能够在iPad等终端设备上高效支持实时视频理解。
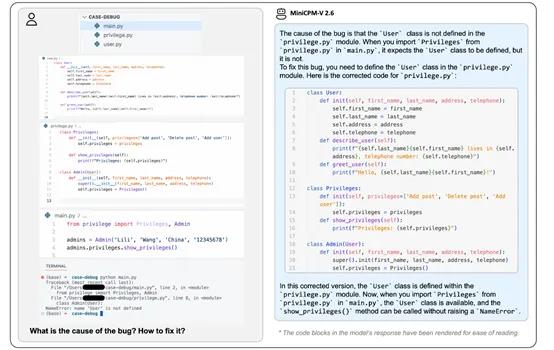
易用扩展性强:可以通过多种方式轻松使用,包括llama.cpp和ollama支持在本地设备上进行高效的CPU推理,提供int4和GGUF格式的量化模型,支持vLLM进行高吞吐量和内存高效的推理,支持在新领域和任务上进行微调
目前,MiniCPM-V2.6在Github的评分超过9000颗星,是开源多模态中性能非常好用的一款模型。
本文素材来源OpenBMB,如有侵权请联系删除
END
更新于:4个月前