
超越恐怖谷!全球500万网友被骗,爆火TEDx演讲者没一个是真人?
【新智元导读】最近,这几位TED演讲者,在外网形成了病毒式传播,然而,他们竟然全都不是真人?!答案揭晓后,五百万网友简直惊掉下巴。这5张图里,你能发现几个bug?
最近,这些「TED演讲者」在外网火得一塌糊涂,堪称病毒式传播。
仔细看看,你能发现什么问题吗?
答案揭晓——这五个人中,没有一个是真人!
在线寻人的小哥要哭了
如此逼真,几乎毫无破绽,这种级别的生图AI直接让网友们惊掉下巴。
甚至连AI识别软件,都认不出来这是AI生成的图。
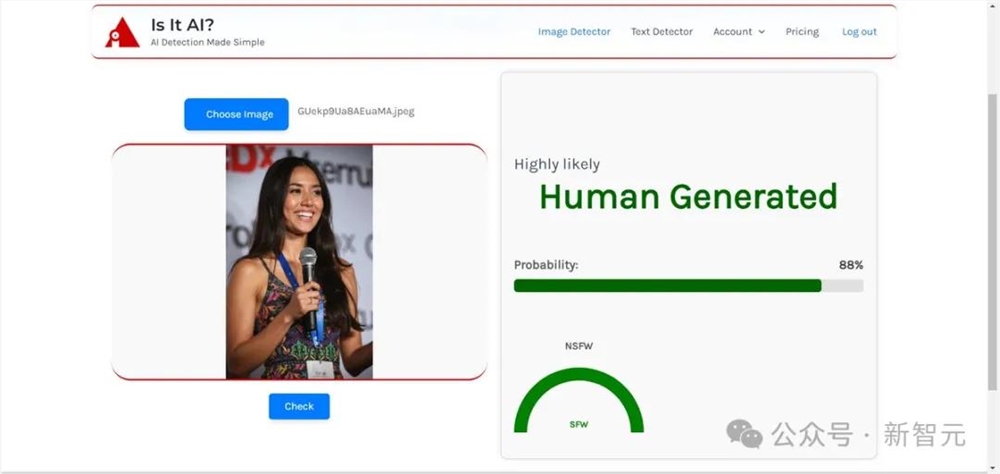
「看起来真实,难道不是因为本来就是真实的照片?」
「没有一张是真人吗?简直令人毛骨悚然!」

网友锐评:这已经超越了恐怖谷,到达了「超真实谷」。

短短十几个小时,分享这张图片的帖子,在推上的观看人数已经破了500万。
随后,作者也被扒了出来——他就是Stable Diffusion团队的前成员Leo Kadieff。
他揭秘道:这些TEDx演讲者,都是用最新的Flux真实版LoRA制作的。
以往的AI生图,人眼多少都会看出违和感,而这次的图片如此逼真,正是靠LoRA技术改进了模型,才大大增加了真实感。
并且,作者介绍说,这个工作流还有一个好处,就是大大简化了复杂的提示词。
这个消息,简直让提示词苦手们狂喜。
这个小小的22MB文件,就可以让我们省去麻烦,不必再在每个提示词中写一堆与真实性相关的Token。
一句「一张RAW超现实主义照片,UHD,8k」,足矣。现实主义爱好者,绝对爱死了这个工具。
作者直言:我们还需要对现实模型进行微调吗?
- 这些图像是Flux+LoRA的原始输出,未经过任何放大或后期处理
- 你需要对应的「RealismLora」文件,以及ComfyUI工作流

Lora:https://huggingface.co/XLabs-AI/flux-RealismLora/tree/main
ComfuUI:https://we.tl/t-zrC5tPFG17
真实版LoRA,效果拔群
从下面这两幅图中不难看出,用LoRA和不用LoRA的效果对比,果然十分明显。



网友已玩嗨
与此同时,「TED演讲者」的分享者Kyrannio,也尝试用Midjourney复刻了一波。

最初的提示词如下:
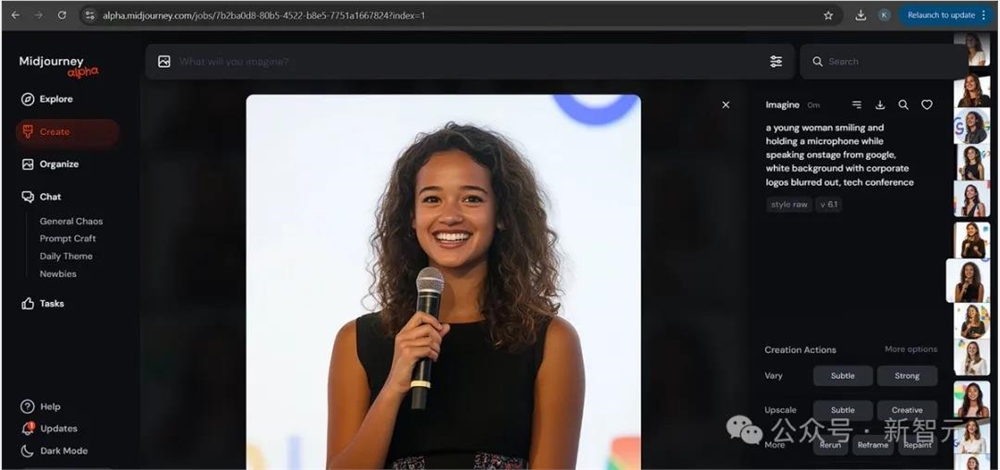
一位女性在舞台上发言,来自谷歌,白色背景,企业标志被模糊处理,科技会议 --style raw --v6.1
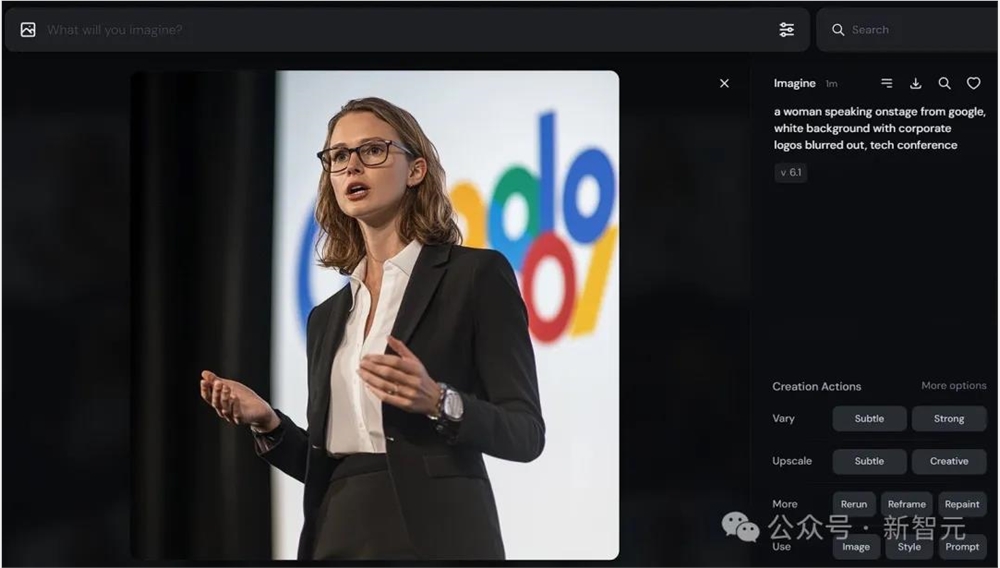
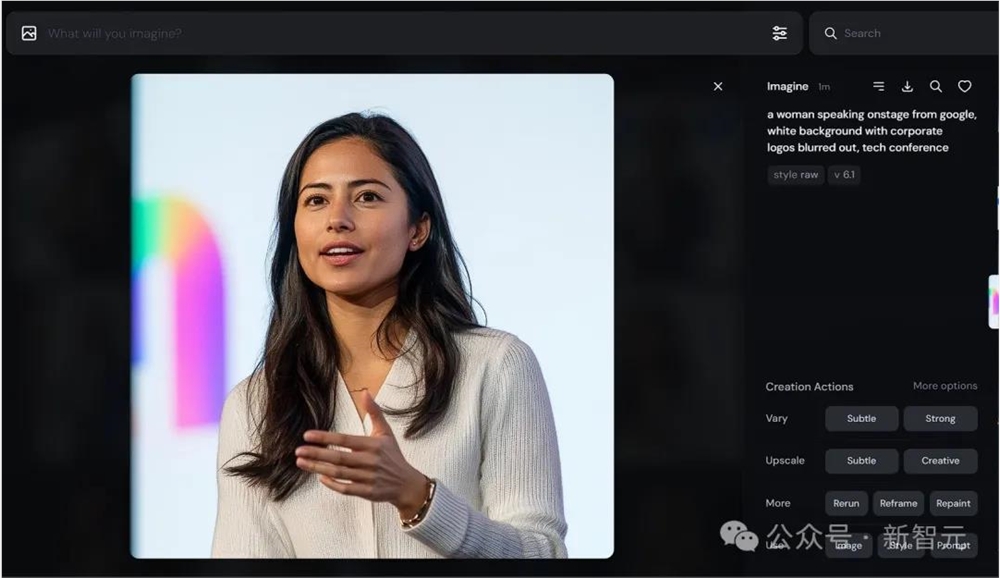
可以看出,生成效果还不错,但与Leo Kadieff生成的图片差距依然很大。
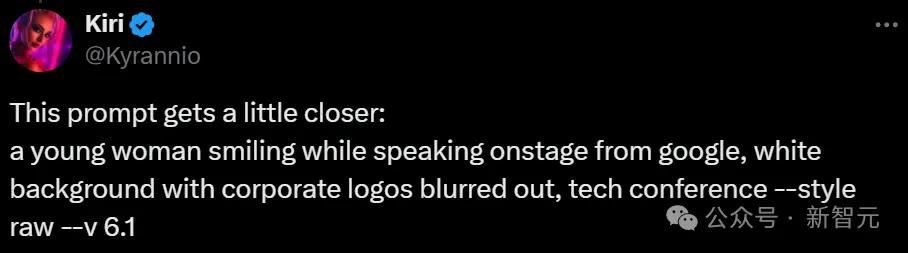
接着,博主又进行了一些改进:
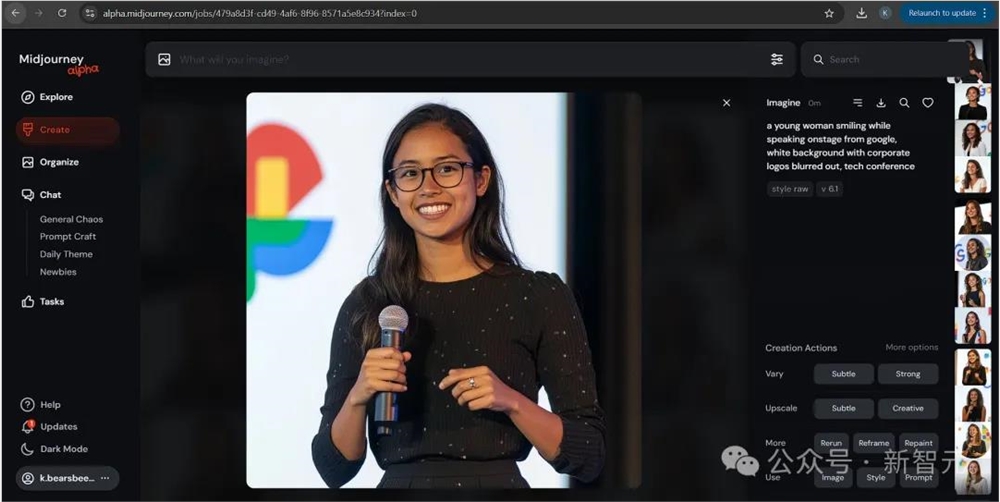
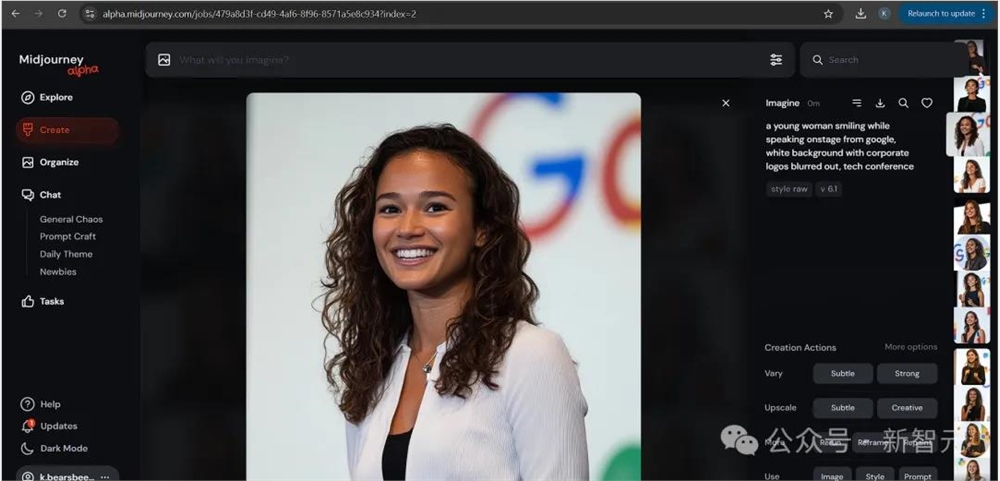
一位年轻女性微笑着在舞台上发言,来自谷歌,白色背景,企业标志被模糊处理,科技会议 --style raw --v6.1
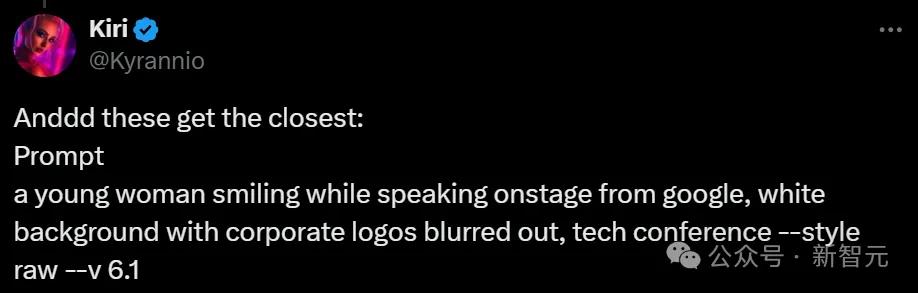
并在经过多次生成之后,试出了最为接近的结果:
与此同时,随着谷歌Imagen3公开可用,网友们也在第一时间拿着这套prompt进行了尝试。
一时间,全网都掀起AI生图的热潮。

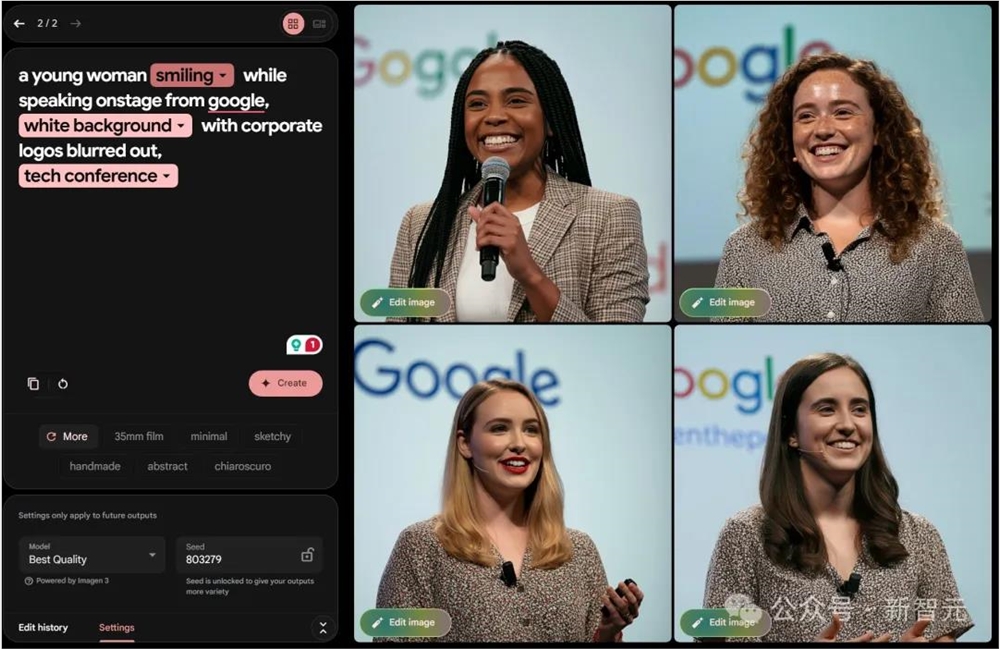
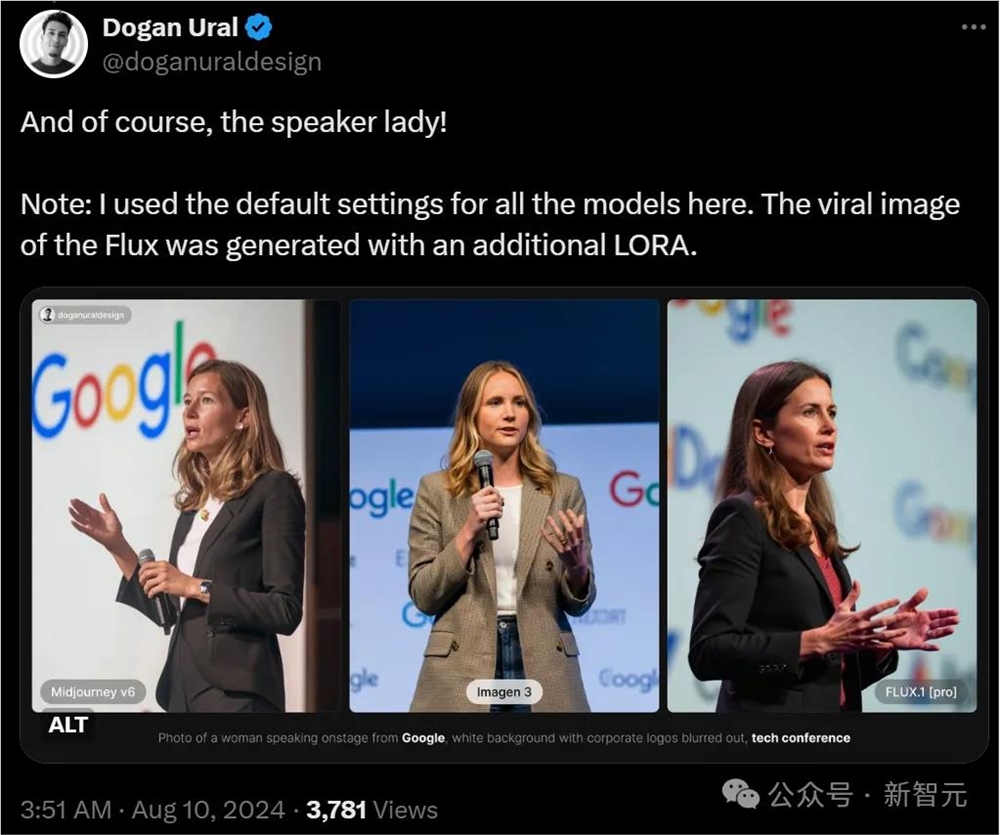
Imagen3全员可用
没错,正如刚刚提到的,谷歌最强文生图模型Imagen3已经正式开放可用了。
prompt:Photo of a man holding a sign that says: Imagen Is Now Almost As Good As Midjourney in New York City.

来源:Risphere
网友chrypnotoad表示,自己还没见过哪个AI能把阿喀琉斯之盾做得这么好的!

能轻松hold住如此复杂的prompt,Imagen3果然不能小觑。
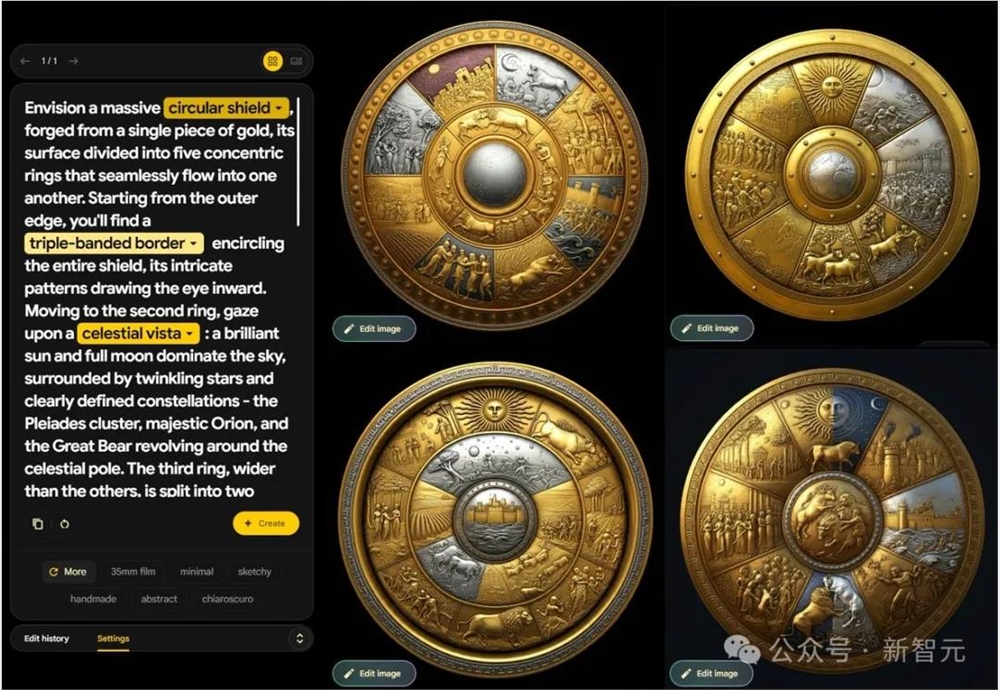
知名博主「歸藏」在体验之后表示:
生成的内容准确但图片美观度很差。只要涉及人物,你就得仔细斟酌提示词写法,不然大概率无法出图。
好在,他们在提示词的交互上做得很好:
LLM会分析提示词类型,并且给出相关词语你可以直接切换。
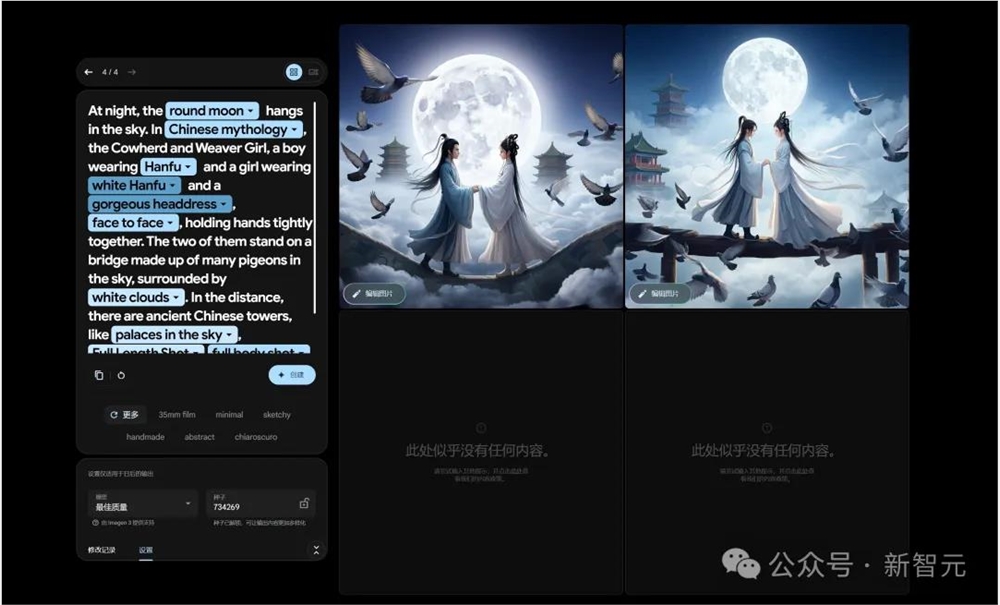
来源:歸藏
除了直接生成之外,Imagen3还支持局部重绘功能,用画笔和提示词对图片进行编辑。
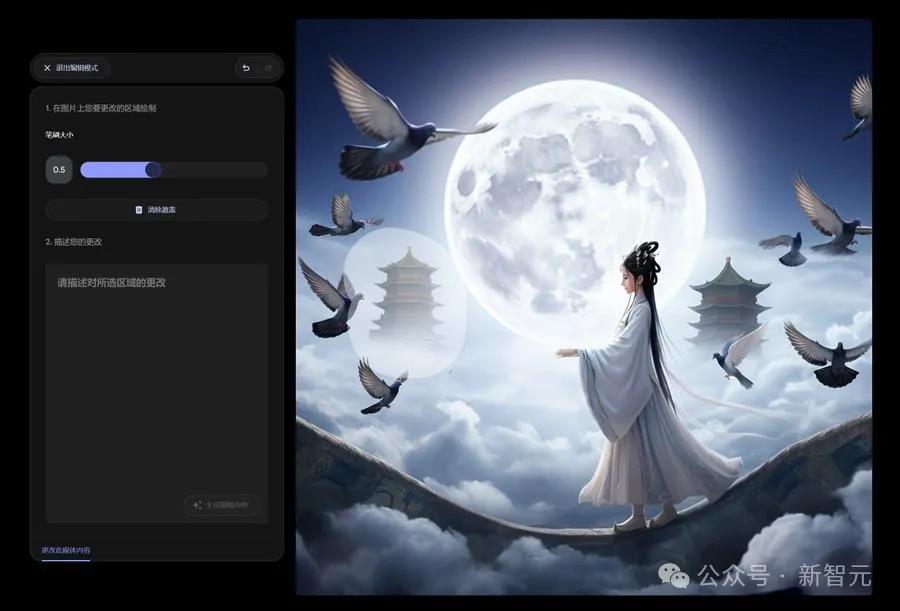
来源:歸藏
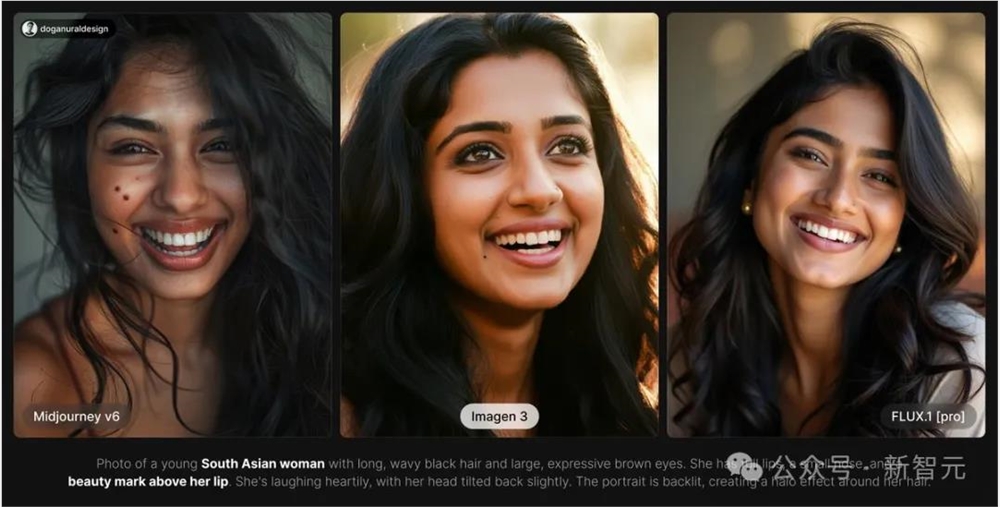
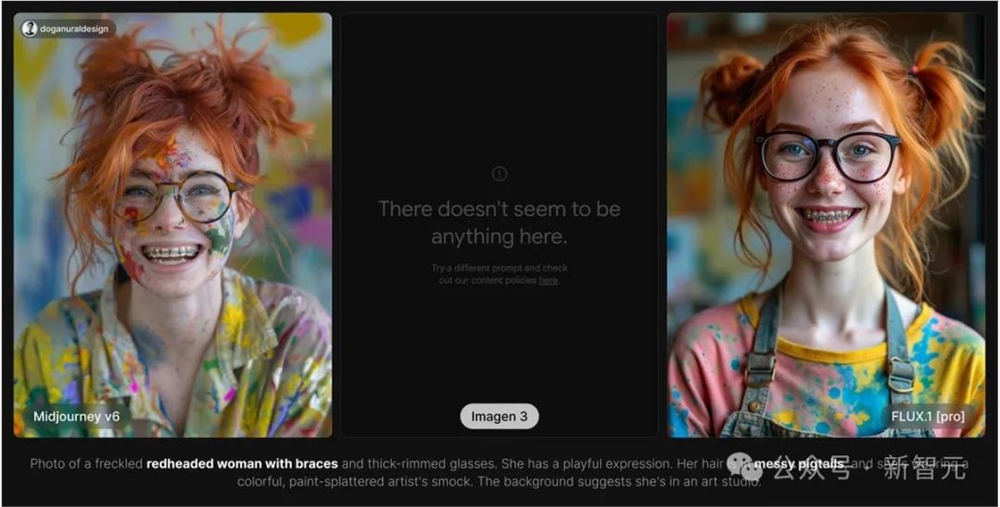
当然,几家顶流文生图AI的PK,肯定也少不了:Midjourney V6vs Imagen3vs FLU.1[pro]。

异色瞳的亚洲女性。

美洲原住民。

有美人痣的南亚妇女。
疯狂的艺术家。
很遗憾,谷歌大概因为安全设置过于敏感,并不能生成这个prompt……
留着八字胡的高加索老人。

Runway也来蹭了一波,但…
趁着这股热度,Runway创意总监Nicolas Neubert,还用自家的Gen-3Alpha生成了一段视频。

果然,AI图片变成视频后,效果依然杠杠的!

而这个帖子,也同样引起了轰动。

网友赞叹道:从一年半前惨不忍睹的威尔·史密斯吃意面,到今天这个程度,进步可谓是疯狂的。
同时,也有火眼金睛的网友发现,这个视频依然有一些细微的bug。
比如人的舌头不会动,牙齿有些弯曲、扁平,第4秒时左臂出现了奇怪的斑点,还有Google标志处的bug,也非常明显。
如果看得再仔细点,会发现所有的阴影都很不自然,比如麦克风的阴影。还有东西接触的地方,很多线条是乱的。
嘴唇的动作也不自然。
眼睛看起来仍然没有灵魂。

总的来说,相比于AI生图,目前AI视频的bug显然要多得多。
背后的原因还是在于,AI根本不理解人类的舌头、头发、眼睛究竟是什么东西。接下来的AI,还是要学会人体解剖和物理学才行。
而且,在文生图这块,Runway就要差得多了。
SD一作携原班人马创业,一出手就是王炸
说回到FLUX.1,其实在8月初的时候它就引起过一波热议。
Stable Diffusion一作、Stabililty AI核心成员Robin Rombach下场创业,官宣成立Black Forest Labs。
祭出的首个产品FLUX.1系列模型,效果直接秒杀Midjourney、DALL-E和Stable Diffusion!
根据官博的介绍,FLUX.1在图像细节、提示词遵循、风格多样性和场景复杂性方面都取得了SOTA。
尤其是FLUX.1[pro],经过测试在一众文生图模型中拔得头筹。
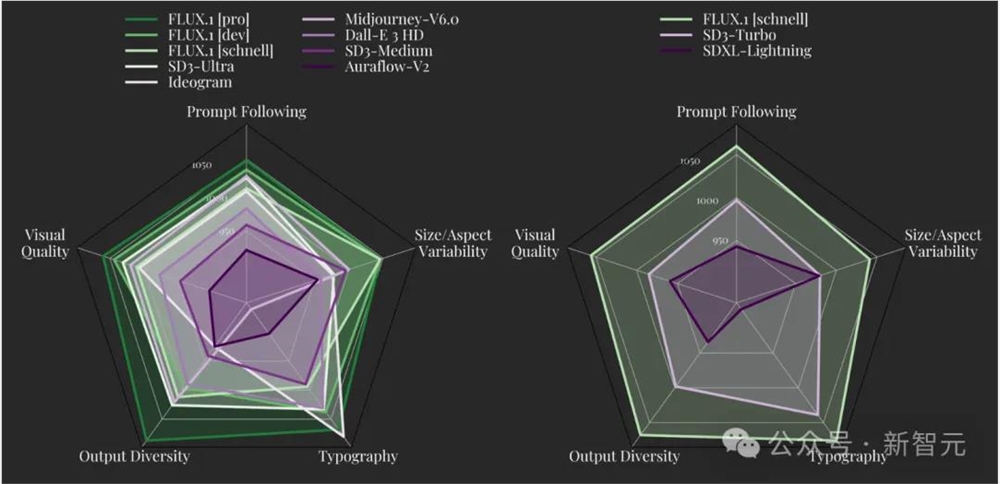
视觉质量、提示词遵循、尺寸/纵横比变化、排版和输出多样性

ELO得分
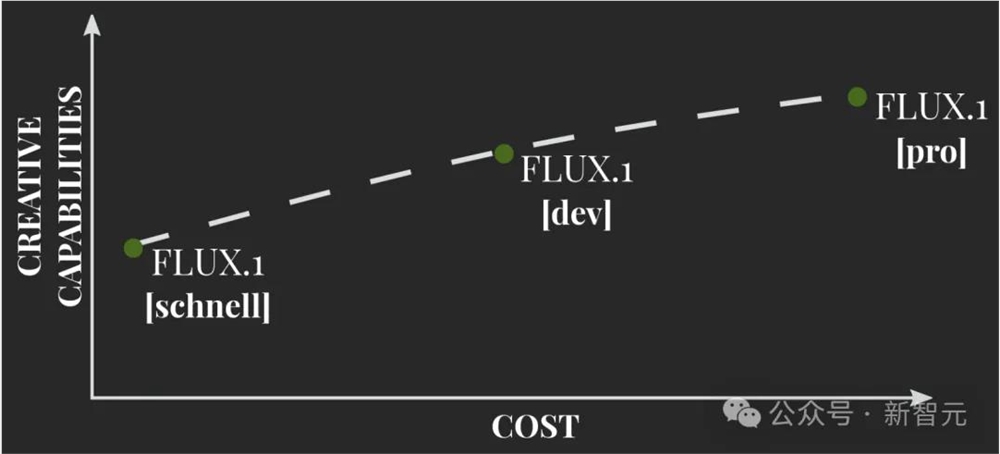
为了在可访问性和模型能力之间取得平衡,FLUX.1有三种变体:FLUX.1[pro]、FLUX.1[dev]和FLUX.1[schnell]:
- FLUX.1[pro]:FLUX.1的顶级版本,提供最先进的图像生成,具有一流的提示词跟随能力、视觉质量、图像细节和输出多样性。
- FLUX.1[dev]是一个开放权重的指令蒸馏模型,用于非商业应用。由于是从FLUX.1[pro]直接蒸馏而来,因此FLUX.1[dev]不仅获得了强大的质量和提示词跟随能力,而且比同规模的标准模型更加高效。
- FLUX.1[schnell]是最快的模型,专为本地开发和个人使用而设计。(schnell在德语中就是快的意思)
值得一提的是,所有FLUX.1模型都基于多模态和并行扩散Transformer块的混合架构,参数规模为120亿。
其中,团队通过构建流匹配(flow matching)改进了之前的扩散模型,并且通过结合旋转位置嵌入(rotary positional embeddings)和并行注意力层提高了模型性能和改进硬件效率。
团队成员
扒开Black Forest Labs主页,可以看到团队共有15位成员。

创始人正是老熟人Robin Rombach。
Stability AI曾收购了Robin的Latent Diffusion模型,并聘请他成为首席科学家。
在Google Scholar网站上,Robin Rombach参与论文《High-Resolution Image Synthesis With Latent Diffusion Models》已经收获了9000多次引用。
期间他领导了全球著名文生图开源项目Stable Diffusion系列,这也是全球下载最多、使用最广的开源大模型之一。

论文地址:https://arxiv.org/pdf/2112.10752
Andreas Blattmann、Patrick Esser、Dominik Lorenz三人皆是SD论文作者,也是Black Forest Labs创业团队的新成员。
除了Bjorn Ommer,可以说Robin将SD核心元老全都带走了。
《Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation》,正收Robin离职前发表的最后一篇论文。

论文地址:https://arxiv.org/abs/2403.12015
值得一提的是,在这篇论文中,Andreas Blattmann、Tim Dockhorn、Axel Sauer、Frederic Boesel、Patrick Esser也参与了其中。
除此以外,新团队曾经的创新成果包括创建VQGAN和潜在扩散(Latent Diffusion)、用于图像和视频生成的SD模型(SD XL 、SVD)以及用于超快速实时图像合成的对抗扩散蒸馏(Adversarial Diffusion Distillation)。
看来,AI生图和视频的进步速度,还在不断加快。
再过一年,我们能看到的AI图片和视频,将是惊人的。
参考资料:
https://x.com/koltregaskes/status/1821984829065588891
https://x.com/doganuraldesign/status/1821992421770850523
更新于:4个月前