
性能秒杀SD3、DALL·E-3,开源文生图模型杀出大黑马
昨天Midjourney刚进行大更新,今天文生图片开源领域就杀出了一匹大黑马—FLUX.1。
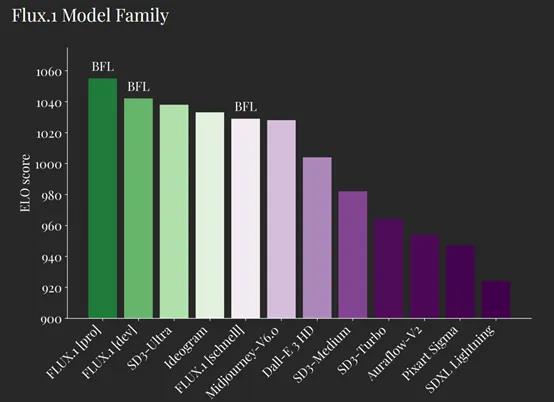
根据其测试数据显示,性能大幅度超过了DALL·E-3、Midjourney V6闭源模型,开源SD3系列的Ultra、Medium、Turbo和SDXL被全线秒杀。
并且FLUX.1表示,文生图只是一个开始,未来还会推出文生视频模型想和Sora、Gen-3、Luma等一线产品过过招。
开源地址:https://github.com/black-forest-labs/flux
在线demo:https://replicate.com/black-forest-labs/flux-pro
出道即巅峰专找最硬的打,有点乔峰横扫聚贤庄的意思。原来刚成立的FLUX.1的创始人是老熟人Robin Rombach。
Robin是扩散模型领域的权威之一,其代表作有VQGAN、 Taming Transformers 和Latent Diffusion。
后来,Stability AI收购了Robin的Latent Diffusion模型,并聘请他成为首席科学家,期间他领导了全球著名文生图开源项目Stable Diffusion系列,这也是全球下载最多、使用最广的开源大模型之一。
今年3月末,Stability AI因资金、运营等问题闹“兵变”,联合创始人被罢免,而Robin也选择了离开。
在沉寂了4个月的时间,Robin成立了新的开源大模型平台FLUX.1,并且已经获得了Andreessen Horowitz领投的3100万美元种子轮。估计以后还会获得大金额融资。

FLUX.1的基础架构是基于Vision Transformer,使用了流程匹配训练方法,同时使用了旋转位置嵌入和并行注意层来提高模型的性能和硬件利用效率。
FLUX.1有120亿参数,本次一共发布了三个版本:1)Pro版,通过API使用;2)dev版,这是一个非商用的指导蒸馏模型,继承了Pro版多数性能;3)schnell版,可以商用的开源模型。
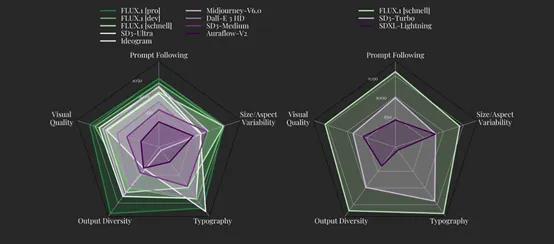
虽然FLUX.1有三个版本,但在文本语义还原、图片质量、动作一致性/连贯性、多样性等方面超过了Midjourney v6.0、DALL·E3、SD3-Ultra等主流开闭源模型,整体性能非常强劲。此外,在文本嵌入图片方面也比这些模型表现的更好。
以下是FLUX.1模型生成的图片展示。
在一个凌乱的小卧室的墙上,有一个通往魔幻森林的大门。

一张旧教室里黑板的照片。黑板上用粉笔写着“让我们一起做一些非常漂亮的东西”,词后有一个红色的粉笔心,阳光从窗户照进来。
水下场景中,两只猫头鹰坐在一张精美的餐桌旁,餐桌中央点燃了蜡烛,两只猫头鹰正在一起享用一顿美味的晚餐。左边的猫头鹰穿着燕尾服,右边的猫头鹰穿着漂亮的裙子。
背景中有一艘潜艇驶过,其侧面画着“What a Hoot”字样。桌子下面的图像底部有小水母在游动,电影般美丽的数字艺术品。
两只穿着维多利亚服装的可爱蜘蛛正在举办一个微型茶会,叶子上有一张小桌子和茶壶。
一位女足球运动员,穿着一件阿迪达斯的球衣,周围是其他运动员模糊效果。
一位三十多岁出头的女子在八角形木制舞池中央弹奏手风琴,舞池有一个木制屋顶,周围是成对跳舞的舞者。
一个超级巨大的黑森林蛋糕,大小如一栋建筑,周围环绕着黑森林的树木。

一个穿着红衣斗篷的超人,在浩瀚、多彩的宇宙中飞行。
很多人都非常看好这个新模型。

一次性发布三个模型,确实让人兴奋。

这V1版本刚发布,就已经有人期待V2版本了。
怎么样,FLUX.1生成的图片质量、细节和光影效果还行吧,期待一下他的文生视频模型。
更新于:4个月前