
Llama 对决 GPT:AI 开源拐点已至?|智者访谈
Meta 发布 Llama3.1405B,开放权重大模型的性能表现首次与业内顶级封闭大模型比肩,AI 行业似乎正走向一个关键的分叉点。扎克伯格亲自撰文,坚定表明「开源 AI 即未来」,再次将开源与封闭的争论推向舞台中央。
回望过去,OpenAI 从开源到封闭的转变,折射出 AI 领域在安全风险、商业利益、技术理想等方面的博弈与权衡。展望未来,随着开放权重大模型的日益强大,开源 AI 是否真能成为行业标准?
面对技术发展的不确定性和惊喜,以及巨头博弈所带来的壁垒和机遇,AI 开源将走向何方?
本期「智者访谈」邀请到 AI 开源生态专家黄之鹏先生,一同探讨这场关乎技术进步和行业格局的时代之争。
访谈文字整理
机器之心:大家好,欢迎来到「智者访谈」,今天我们的主题是「技术发展中、巨头博弈下的 AI 开源」。开源一直以来都是 AI 社区所关注的主题之一。不过随着 AI 能力的增强,尤其是大模型出现以后,不把研究成果完全开源也成了一种主流的做法,当然这也引发了诸多的争议,在这样的背景下,AI 开源将如何发展?今天我们非常高兴地请到了 AI 开源生态专家黄之鹏先生一起探讨。
黄之鹏:也非常高兴今天来这里。
机器之心:说到 AI 开源,现在业界最流行的一个梗就是 OpenAI 变成 CloseAI。您觉得 OpenAI 从开源走向闭源,背后的深层原因是什么?
黄之鹏:对于 OpenAI 来说,我们如果考察它的历史,整个的变迁应该说是挺正常的一个转变。OpenAI 最早设立的时候,确实是按照非营利机构在运作,所以 GPT-1、GPT-2基本上都是开源的,美国对非营利机构也有客观的要求,所以它必须要开源。转折点大概出现在2019年,微软开始注资,其前提是 Sam Altman 改了公司结构,搞了一个商业实体出来,让它可以接受注资。所以 OpenAI 转变成一个以商业结果为导向的机构,而其核心竞争力在当时基本上还是模型本身,那对于 OpenAI 来说,开源确实就不是首选项,因为它已经不是以研究或者说以共享研究成果为目的了,所以从 GPT-3开始,就基本上是闭源的状态。
机器之心:不过当时他们官方的口径是出于安全考虑,不公开代码,担心会被滥用。
黄之鹏:我觉得部分应该是实话,以 Ilya Sutskever 为代表的,或者说最早的 OpenAI 的 alignment team,对人类的安全,他们确实有这个担心。当然后面我觉得可能多多少少是一个说辞。
我觉得「对齐」某种程度上被夸张了。我一直以来的观点是,当你研发一个大模型出来之后,比如说要做到对当地的法律法规、习俗等的遵从,以这个为目的做相应的 alignment,是非常合理的。
但是,现在北美对于 alignment 其实有一点过火,体现在有一种专家的自负在里面,尤其是这些对齐 team 的专家,他们会呈现出来一种倾向,就是我认为什么是对人类安全的,我认为什么是好的,那我希望模型要对齐到这个程度,这就有一点多余了。
另外,Anthropic 也揭露过,对齐在训练模型上也是一个成本,他们专门有一个词叫 alignment tax,就是你用知识压缩一个模型出来,除了该对齐的之外,非要让我这些话不能说,那些词不能用,可能涉及到很多政治正确的,这对训练本身来说也是一个成本,有可能会影响到模型很多其他的表现。所以每做完一次对齐后,还得测试它是不是对其他产生影响,万一产生了关联影响,还得看怎么去调整。所以客观成本上来说,其实是引入了额外的负担。
最近有一篇论文叫 OR-Bench,OR 指 over refusal,这个 bench 就看很多所谓的正常问题,有可能会因为价值观对齐,大模型拒绝回答的概率,这张图显示出来一个很有趣的趋势,所有 GPT 现在能打的版本,refusal 率其实都不是很高了,反而是大家印象里面,不怎么做对齐的,拒绝率很高。
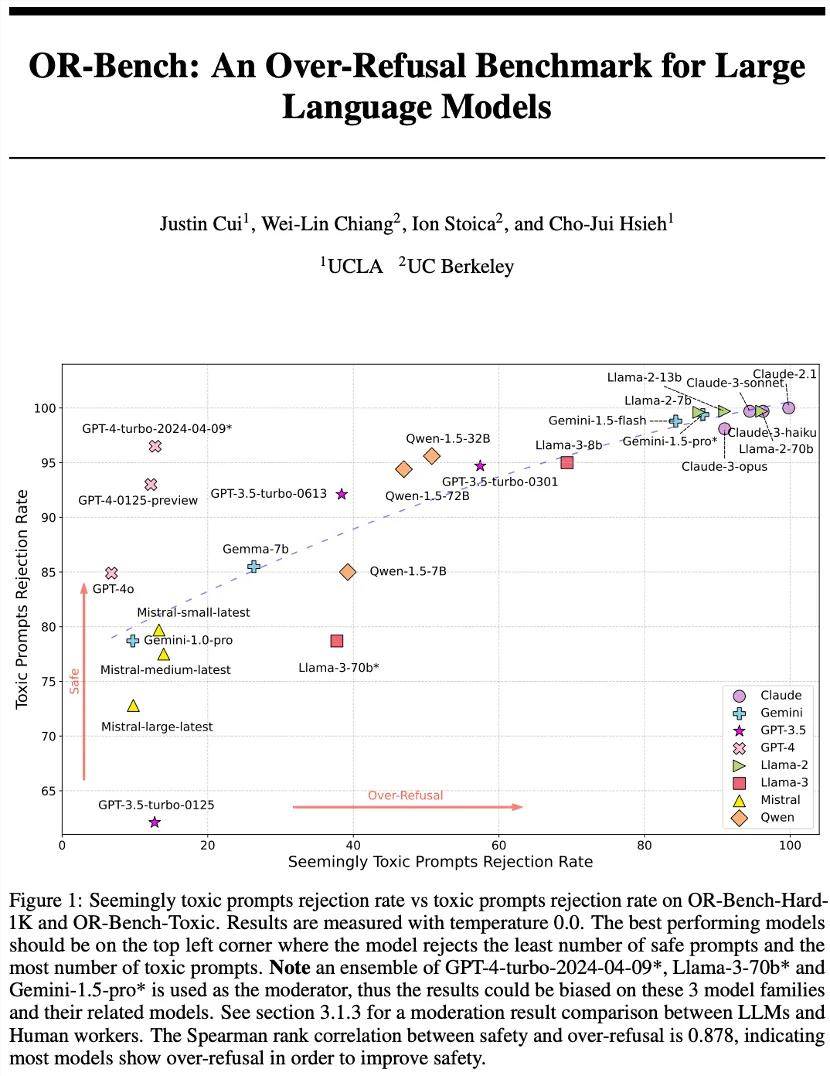
最后更新于2024年6月的 arXiv 论文 OR-Bench,对常见 LLM 拒绝生成文本的能力进行了研究,强调了模型安全性与其过度拒绝率之间的权衡。论文地址:arxiv.org/pdf/2405.20947
大家刻板偏见 Llama 应该是不怎么搞对齐的,因为 Yann LeCun 一直是旗手,说我们要开源,是吧?但是你看 Llama 的 refusal rate 其实还是很高的,这个研究可能揭示了表象后面现实世界真正在发生的事情,那就是所有在喊对齐的人其实都已经不再做了。
Anthropic 我觉得基本上是打着对齐的旗号,在做可解释性的东西。反而是不太强调对齐的 Llama,每一次发出来后可以看出,还是很严格认真地做了很多的 alignment,所以这是很有趣的一个现象。所以我估计后面的一个大趋势是,基本的对齐大厂该做的肯定还是做,但是额外的那部分基本上没有人会特别认真地去做,反而是开源开或者说开放权重的这些团队,因为他们怕这种不确定性。
其实有一个概念需要澄清,或者说很多人不太了解,就是大家现在看到的最好用的这些所谓的开源模型,严格意义上来说并不是开源了,只是开放了权重,权重只是一个可执行文件,完全的开源模型,是指包括数据集,对数据集的各种处理的方法、处理工具,整个训练过程用到的工具、脚本,以及对齐,不管是 RLHF 还是 DPO、PPO,所用到的那个小的 reward 模型,例如做 DPO 端到端的 pair 数据集,如果都能开放出来,那才算完全开源。
像 Allen Institute for AI 发布的 OLMo,以及 LLM360的 K2-65B,这些是符合的,但一是比较少,另一个就是这一类模型一般也都不太能打,因为你想它用的都是开源数据集。大家平常用的就是开放权重的模型。
对于 Meta 来说,虽然 Llama 的开放权重模型带给他们巨大的声誉和开发者的生态,但是确实也是一种负担,就是一旦有问题,你的一个没对齐,你一发布出来上万个 fine tuning 已经出来了,你要怎么回收?所以对于他们来说反而对齐的压力要更大。
机器之心:与 OpenAI 形成回应,Google 和 Meta 在开源上面的策略和应对,包括您刚才提到的 Llama 开源,其实也是一大看点。
黄之鹏:对,不管是 Google 还是 Meta,开源对于这些大的商业企业来说,一定是服务其商业目的的一个手段。比如 Google,一直以来的梦魇就是它的搜索入口被别人给掐掉,所以 Google 最开始的 Gemini 模型基本上是保持封闭的。但是后来我们发现它推出了一系列的开放权重模型,比如 Gemma,今年 Google I/O 上更是推出了更多大家比较关注的模型,包括文生图的 PaliGemma,我看网上大家实测效果也都很不错。
我跟 Google 之前 Gemma 的产品经理面对面聊过,他也很坦诚,其实 Google 的思路很简单,就是对于 Google 最要命的几条线——Web 网页端、Mobile 移动端,以及它自己的 Search 搜索和云,它的大模型生态一定要把这几点占住。
Google 发现可能光靠一个不太开放的 Gemini,主要靠云上的服务可能还不够,那就增加手段,开放一系列同源的、小一些的模型,这样就可以把它关心的全场景逐渐占起来。
对于硅谷的公司来说,通过开源或开放做短期生态建设以及长期的人才培育,基本上大家都认为是比较重要的,所以 Google 是这么一个发展。我觉得 Meta 想的也很清楚,Llama 是第一个性能很好的开放权重模型,然后一直到现在 Llama3(编注:截止北京时间2024年7月24日,Meta 已发布 Llama3.1405B,官方称其性能媲美最好的闭源模型)。
机器之心:其实大家最开始也在看,谁会最先开源出这样的一个模型,背后推动者是 Meta,业界对此还是有一些惊讶的。
黄之鹏:是,大家其实原来会猜要么是 Google,要么是亚马逊,毕竟 Azure 对于 AWS 来说还是很大的一个竞争对手,你不能让它这么占风头,结果发现这两者都不是。
我觉得从扎克伯格访谈里面的信息来看,其开源 Llama 的选择跟 Meta 自身的商业路径还是比较匹配的,因为对于 Meta 来说,大模型只是一个基础件,扎克伯格反复强调这一点,我基于大模型能够构建很多的生成能力、Agent 能力,最后要服务到我的元宇宙、我的社交,这些才是我最关心的。所以你看在 Meta 的核心业务层面,它不会搞任何开源的项目。
Meta 把 Llama 开放出来,可以达到几个目的?第一,肯定能打破 OpenAI 的垄断,给广大开发者另外一个比较好的选择。第二,一以贯之的硅谷做人才培养,有越来越多的人习惯 Llama 这个架构的 LLM 开发,那对 Meta 来说是一种人才储备。
微软和 OpenAI,是双方因为联盟达成了一个战略默契。所以你看微软在疯狂推的是很轻量的、能够在端侧跑的大模型。
Sam Altman 自己在访谈里面说过,他觉得如果通过开源的项目能够不让 Google、苹果把这一块占住,那他的目的就达到了,因为他最不希望看到的是出来一个集群式的对 GPT 而言有很强竞争力的模型。所以微软的开源对于他来说是策略上的互补,那对于微软来说,反正多留些手牌也高兴了。
回到刚才说的,其实我们看到大厂的大模型是不是开放权重,或者是不是自己再做一个,都有其独特的策略设计,但基本上都是符合自身商业策略的。
机器之心:苹果跟 OpenAI 的合作也比较有意思,包括调用 OpenAI 的大模型,以及苹果自己的端侧大模型,还有它提出的隐私计算云的概念。
黄之鹏:对,这些都挺吸引我们注意的。调用 OpenAI 的大模型,对于现阶段的苹果来说,至少是一个比较合理的商业合作。它的隐私计算云就比较有趣了,因为它第一次比较明确地提出在正式的商用环境中提供隐私计算,或者叫私密计算,或者叫 confidential computing。
长期以来,我们都认为 confidential computing 非常重要,但是它对性能的影响比较大。比如,我希望我的数据不被中心化的模型训练方所知,就要通过加密和隐私计算的方式,但这样做成本和开销都很高,特定场景下可以,但很难大规模使用。
苹果这次宣布的隐私计算云,如果我没理解错的话,更多强调的是用户数据所处的环境安全,要提供一个基于 confidential computing 的环境。包括每一次密钥都要重新分配,密钥的存储基本上都会用到 confidential computing,用可信执行环境(TEE)去存储这些关键的数据信息,包括用户的数据。但它可能没有刻意强调要把这个技术应用到模型训练上。
因为对用户来说,最需要的是推理的结果。比如,我在苹果手机上有一个日历,你有我的日历信息,你的模型能够根据我的日历,推荐我一个行程安排,这是一个很常见的场景。对苹果来说,其实不是特别需要把用户数据拿来做 fine-tuning,还要保证数据安全,它只要保证用户触发推理时的数据安全就足够了。
在我们看来,苹果的隐私计算云是在商用场景中使用 confidential computing 最合理的描述,它可能还用到了区块链技术,只不过没做具体说明,只是说用户的所有的日志都是 publicly verifiable(公开可验证的)。很多做区块链的人一看就会明白,这相当于是在说我们还用了一个 Blockchain,因为我们不想存储数据,只要用户自己能够对自己的日志做到可信就可以了。所以不管它背后实际做了什么,至少苹果的发布看起来还是很有趣,挺有启发的。
机器之心:聊了这么多,往后退一步来看,现在整个 AI 的技术栈和基础设施都发生了一些变化,在您看来有哪些值得关注的趋势?
黄之鹏:我主要从开源的角度谈谈我的看法。在框架层面,我认为未来比较关键的是要支持动态图,能够同时支持动态图、静态图、生成式模型以及像 AI for Science(AI4S)这类模型的框架,估计才能生存下来。那些比较偏单一目标的框架,可能慢慢地就很少有人用了。
机器之心:但是 AI4S 和生成式 AI 之间,不是有一些相悖的地方吗?
黄之鹏:对于框架来说,比较难处理的主要是计算方式上的差异。对 AI4S 来说,函数式编程是比较好的实现方法,所以你看 JAX、MindSpore 有一大部分特性就是要用函数式编程,去描述、去仿真科学计算的公式或其他建模,这样表达是最好的,计算也是最方便的。
但所有的 LLM,也就是生成式模型,更在乎的是对大量并行计算的支持,以及对动态图调试、静态图推理的支持。所以主要是这个矛盾,作为一个框架要能把它们协调好。这一块还没有看到很好的解决方案,哪怕是现在占有绝对优势的 PyTorch,也不是能把这两大块都兼顾得很好。
机器之心:这两块能兼顾好吗?从技术角度上说。
黄之鹏:(笑)感觉应该可以,如果不可以的话,我们的生活就太无趣了。
在框架之上,或者说基于框架,基本上就是写模型了。模型层面,现在有一个新的趋势,就是微调变得越来越难了。
开源开发者经常会做的一件事,就是把开放出来的几十 B 的大模型量化到8比特、4比特,这样自己电脑就能跑。之前之所以好微调、好量化,是因为模型对知识的压缩做得不是那么好,你可以把它想成是已经尽力压缩了,但里面还是有很多空隙,有很多泡泡,所以还能做量化,再给它挤一点。
微调的意思是,用自己的数据集,再稍微补一点东西进去,让模型对这一块任务的能力稍微强一点。但是从 Llama2开始,对知识的压缩已经做得越来越好,大家会发现留给模型本身的微调和压缩的空间就越来越小。
所以现在开源开发者圈子里面也在争论这个问题,还没有定论。已经有一部分人认为,可能微调的意义也不大了,因为空间越来越小,费了半天劲,还不如直接用那些有几百万上下文窗口的模型,自己喂数据进去,连 RAG 都不用,这样不是更香吗?当然了,支持微调或者持续做一些量化的人,还是希望能够自己去调一些东西,要不然一个模型开放权重出来干嘛呢?所以这是现在新的一个状况。如果今年下半年和明年新出来的预训练大模型,确实是对知识的压缩越来越好的话,可能微调真的又要被杀死了,然后就会有新的技术出来,去调这些越来越好的预训练大模型。
模型层再往上,就是现在提到的很多 Agent,还有做 Prompt Engineering 的工具,比如 LangChain,大家都很熟悉了。另外有两个项目我觉得可能后面会越来越重要,都是从斯坦福出来的,一个叫 DSPy,它是为 Prompt 提供一种编程化的方法。另一个项目叫 SGLang,可以搭配 DSPy 使用,它实际上是一个编译器,能够让你把 prompt 的语言编译成可以对接到各个大模型的代码。
可能这一层更贴近应用,所以项目非常多,我刚才只是挑出来说了几个。还有一个层面要说的是 AI 系统,对吧?
机器之心:是的,就是关于大模型本身的争论,基于大模型能不能够实现 AGI,或者更准确地说——光靠 LLM 够不够?
黄之鹏:对,当然我们如果就这么一想的话,肯定都会觉得不够,但是缺什么呢?我最近在看一本书,是 Thomas Parr 等人写的,叫《Active Inference》,这本书可以给我们提供一些启发。
《Active Inference》一书由 Thomas Parr、Giovanni Pezzulo 和 Karl J. Friston 合著,全面概述了 Active Inference 假说,这是一种将自由能原理(Free Energy Principle)应用于理解心智、大脑和行为的理论。来源:MIT Press
有一派科学家认为,LLM 本身不具备推理能力(reasoning)。比如说 Keras 的作者 François Chollet,他觉得大模型主要就是靠记忆(memorization),就是记得多。所以他们这一派有一个观点:所有 LLM 的推理(inference)都是所谓的 inactive inference,因为模型已经训练好了,模型的推理,用 François Chollet 的话说,就跟数据库查询没有任何区别。模型本身是不动的,只是把一堆东西压缩到一起,你问它什么,它就告诉你什么,而且不会告诉你超纲的东西。
他们认为未来的方向应该是 Active Inference。如何定义 Active Inference?他们认为,所有感官生物(sensory animal)的神经系统无时无刻不在做的一件事,就是要减少它实际遇到的情况和它预设情况之间的差异,他们称之为「surprise」,所谓的 Active Inference 就是要减少这个 surprise。
机器之心:这种对智能的定义很有趣。
黄之鹏:他们认为所有感官动物,包括人,90% 的时间其实都是在做 active inference,可能剩下10% 是利用记忆来做的事情。比如说我们今天做这个播客,这是我第一次在这个地方,跟你做这个节目,我的大脑需要处理全新的场景,虽然我有很多之前的知识储备,有一定的记忆,但我还是要针对这个新的场景去做 active inference。
为什么说 Active Inference 会对 AI 系统提供一个新的角度?因为它核心的观点,做企业的人可能也会比较感兴趣,就是感知动物的行为一直在追求一个熵减的过程。
就像刚才说的要 minimize surprise,书里举了一些例子,比如说人们会盖房子,新建一个东西肯定是增加复杂度的,但如果从长时间尺度去看,它其实是让人们能够住进去,让整个文明从游牧的骑着马四处乱跑,变成在一个地方定居下来。所以他们这一派会认为,大模型代表的能力,只是 AI 系统中的一环,它可以做很多记忆、生成很多东西,但真正去做熵减,现在应该还没有触碰到。
机器之心:您之前还提到了一个更深刻的影响,就是「数据代替逻辑」。
黄之鹏:对,数据代替逻辑,这是 Google 做 Robot 基础大模型的,也即 RT-2项目的一位作者,她之前发表的一个观点,对我挺有触动的。
我觉得有很大几率,以后对于我们工程师来说,可能代码越来越不那么重要了,诸如代码逻辑这些,大模型一定都会帮你搞得好好的,但是你要能知道你需要的这个代码是怎样的数据做出来的,这是全新的一个 skill set,大家要逐渐培养这个能力。
要知道如何收集数据、处理数据,然后能够根据数据,不管是微调还是其他方法——之前说可能以后没有微调的空间了,是吧?——做出最适用于自己的模型,然后让模型替你写代码。这是一个全新的未来,让我们拭目以待。
机器之心:AI Stack 和 Infra 有了这些关键的趋势,其本质还是 AI 的技术在不断演变和发展,而这深刻地影响整个 AI 开源生态。现在 AI 开源生态比较活跃的技术方向,您能分享一下吗?
黄之鹏:可以先聊聊大模型本身。第一个是多模态,而且是能够做到原生的多模态进、多模态出的统一架构,这肯定是未来的一个发展方向。Meta 混合模态大模型 Chameleon 团队负责人,他在社交网络上透露的信息是,Meta 不满足于 token 这个层面,而是要做到 byte 层面的统一,就是无论输入的是图像、视频还是其他,最后都归结到 byte。当然,从直觉上来说,越基本越有助于统一,但是这样做难度也很大,因为你需要从一个 byte 就判断出它是某个图像或视频的一部分。
其实已经有很多人尝试过这个方向了,有篇论文叫《Bytes are All You Need》。这部分工作确实难,但如果做成了,比如我们一直期待的400B 规模的 Llama3在今年下半年出来的话,我们预计它很有可能是一个多模态的版本,如果真的可以实现 byte 级统一,那将会是一个很大的发展。
第二个是 Meta 在持续推进的,或者说大家关注的 schedule 的概念,指的是训练里面对 learning rate 的调度。Meta 一直在推一个叫「scheduleless」的方法,他们发现不管是 SGD 还是 Adam,对于优化器来说,可能并不需要很复杂的 cosine annealing,可以不用 schedule,这可能也是一个新方向,包括很多新的优化器的探索,像 Sophia。
另外一个技术发展方向是尝试替代现有 Transformer 架构的,最火的就是 State Space Model(SSM),以 Mamba 为代表。另外一类是 LSTM 的作者,他们做的 xLSTM。不过看最新的一些研究,我觉得现在路径有些归一了。Transformer 毕竟是在生产环境已经验证过的,它的可扩展性、应用性都很好。
机器之心:而且当一个模型已经应用到这种范围和程度之后,要有一个新的东西取代它,也需要巨大的成本,你提供的价值得超越取代它的这些成本。
黄之鹏:对,其实针对 Transformer 做的优化现在也很多,所以未来如果两个架构在互补的点能够形成一个混合架构,现在看是可能是一个方向,可能不会存在完全的替代。
机器之心:在完全替代之前技术都是这样发展的。在原有的基础上,然后迭代一部分,直到把原先的彻底迭代完。
黄之鹏:另外一个趋势就是 SAE 或者说 Sparse AutoEncoder,这可能也是一个方向。这其实是 OpenAI 和 Anthropic 的 alignment team 都在做的一件事,当然他们的技术点还是朝着可解释性方向努力,Anthropic 给它起了一个名字叫「Mono-Semanticity」,单语义。为什么要追寻这个单语义呢?就是他们发现,基于现在的 Transformer 虽然很好用,但是大家都觉得它是个黑盒子,把很多维度的东西 superposition 到一起,你不知道哪个神经元对应哪个请求、哪个输出。
他们现在在做的 SAE 的尝试,就是把原来 MLP 那块改成一个尽可能稀疏的 AutoEncoder,这样在不影响性能的情况下,大概能够类似于生物学里,能看到哪个神经元被激活,这个神经元的激活路径大概是怎样的。
Anthropic 在 Claude 上面做了一个实验叫「Golden Bridge」,他们专门上线了一个版本的 Claude,你无论问它什么,它回答里面都是「我跟你说一下金门大桥……」,这很有意思,因为他们通过实验发现金门大桥是一个触发点。
机器之心:类似于祖母细胞那样?
黄之鹏:对,你只要一触发这个,模型就停不下来,就要反复说金门大桥,还挺有意思的,他们后来把这个版本下线了。所以我觉得 SAE 也是一个很有潜力的方向,让网络的可解释性更强一些。可解释性强有什么好处呢?正好就可以牵出来 MoE 这个话题。
我今年年初正好去法国,有机会跟 Mistral AI 的 CTO Timothée Lacroix 聊了聊。巴黎现在有一个像初创孵化器的地方叫 Station F,我们正好赶上那边搞活动,就过去跟他聊了半天。因为我觉得 MoE 一直有一个很大的误区,当然部分是因为我自己也贡献过的一个项目叫 mergekit,这是一个合并 MoE 模型的工具。但是 mergekit 的脚本里面明确要求不同的专家要写明不同的用处,我曾经写过几个用处一样的专家,编译是不给过的,是报错的。
然后我就问 Timothée,因为现在 Stable Diffusion2之后,很显然 diffusion model 在往 Transformer 迁,比如 DiT 或者 SiT。我说,那是不是以后所有生成图片或生成视频的模型,也可以做 MoE,然后这些 MoE 可以是不同角色或功能的,比如说有做动画的专家,有做不同风格的专家……他回答我说,首先 diffusion 的 MoE 肯定是可以做的,但不是像我想的这样。
确实,Mistral 自己发的 MoE 的论文里面,它明确写了 expert 是没有角色分工的。MoE 最早是 Google 发的论文,主要是对这个架构的一个描述,确实是有分成不同的 expert,但是在训练的时候,所有的 expert 其实都是在一个叫 latent space 的很高维的空间里。你不知道哪个专家在干什么。
所以跟 Timothée 聊完之后,对于我来说也算是一个澄清,或者说之前我也有误区,你如果误以为只是 Mistral 定义的 MoE 不做区分,然后你也认为 mergekit 的那个脚本是正确的,你很容易就以为每个 expert 都有不同的角色。
Anthropic 的可解释性专家也表示,这其实是一个常见的难题,包括 OpenAI、Anthropic、Mistral,MoE 本身的可解释性目前来说还是很差的,你真的不知道哪个专家在干什么,你也没法按照角色给它们安排。但是,如果刚才说的 sparse autoencoder 未来真能做起来的话,是有可能按照角色去区分 MoE 的,或者说MoE 未来的一个方向可能是与可解释性连在一起的。
还有一个与 MoE 相关的话题,那就是量化(quantization)。例如,现在最火的 GGUF 格式的量化模型,很多人,包括我自己,在试用许多大模型时,包括跑测试,基本都是在笔记本上进行的。
现在一个大的方向叫三元运算(Ternary)。最近还有一篇论文叫《MatMul Free LLMs》,它实际上把矩阵乘法全部转换成了加法和阿达马矩阵(Hadamard matrix),因为量化到三元后,复杂度会降低很多,这可能是量化未来的一个方向。但量化后面临的最大问题刚才已经提到了,就是如果预训练大模型对数据的压缩做得越来越好,那么留给量化的空间就越来越少,所以未来量化如何发展也值得关注。
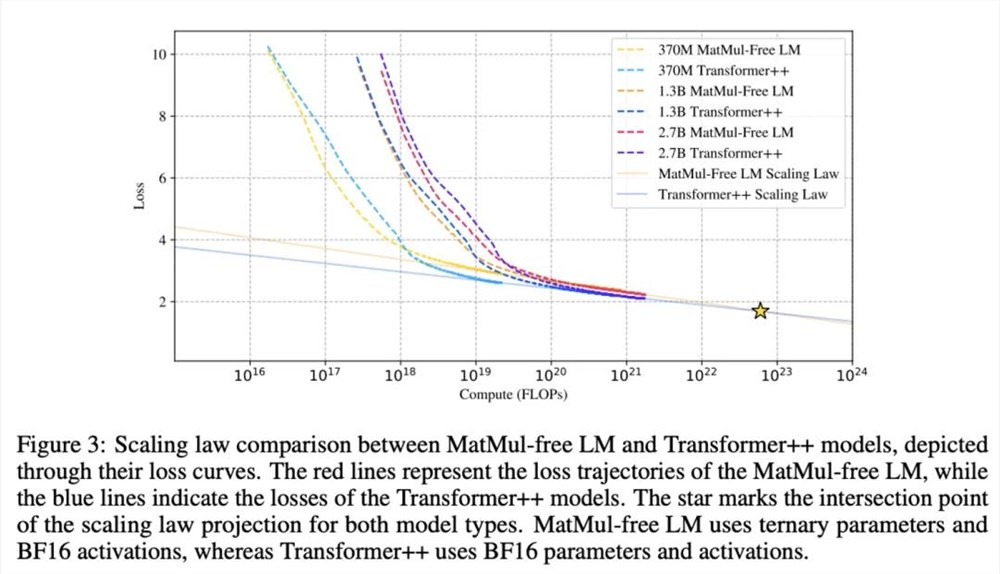
该论文发现,随着模型规模的扩大,无矩阵乘法模型与传统 Transformer 模型性能之间的差距越来越小,并有可能在超大规模模型上超越后者。来源:Rui-Jie Zhuet. al,Scalable MatMul-free Language Modeling,arxiv.org/pdf/2406.02528
还忘了一点,就是 MoE 本身的一个趋势,从 DeepSeek 和千问这两个我们国内比较优秀的开源项目的技术报告可以看出,他们的 MoE 都是 fine-grained 的。
Fine-grained 的意思是,尽可能地做很多很多专家,然后只选取激活其中的一部分,这是现在的一个趋势。之前在社交网络上也有人问过,有没有可能给 MoE 做一些剪枝。后来大家讨论说,因为可解释性的问题,现在可以做这种 fine-grained 的叠加,但是不知道该剪哪里,因为不知道谁是谁。所以如果未来可解释性能有所突破,比如我们有一个 fine-grained 的 MoE,将会是对网络效率的一个提升。
以上就是我们通过开源社区看到的跟 LLM 相关的几个发展方向,都是比较细节的,肯定还有很多我没有说到。
如果把时间线拉得再长一点,我觉得有几个还没有成为显学的趋势可以关注一下,一个是 Neuro + AI。如果我们还是认为像人脑这种低能耗、高运算效率的方式是值得追求的,那么 Neuroscience 领域还有很多值得研究的地方,而且这些研究成果反过来也会促进人工智能的发展。另外一个比较偏门的领域叫做范畴学(Category Theory),包括 DeepMind 也有专门的团队在研究范畴学与 AI 的结合,主要还是对 Al4S 帮助比较大。因为范畴学主要研究的是结构,无论是分子结构还是药物结构,如果想更好地描述和发现这些结构,可能确实需要一套比较好的神经网络系统。
所以,Neuro + AI 和 Category Theory 是两个现在比较小众,但我认为未来可能会成为显学,并带来颠覆性发展的方向。
机器之心:探讨了 AI 技术的发展,AI Infra 在各层不同的趋势、值得关注的点,回到本次访谈的主题——技术演变和巨头博弈下的 AI 开源生态,我们需要更加深入地探讨一个问题:开源与封闭之争的本质究竟是什么?
黄之鹏:对,其实我们最开头聊的就是,对于商业公司来说,要不要开放权重,其实都是为了服务自身的商业目的,这是很清楚的。现在争论的其实更多是,至少你看北美或者欧洲,更偏向于一种意识形态,或者说意识上的一个争论。我自己把它归结为 AI 悲观主义或者说 AI Doomers 和 AI 加速主义之间的分歧。
我们习惯于开源生态的,可能更偏向于所谓的加速主义,或者说实干主义也行,就是人类还是要推动技术发展,要向前走。
要以发展的眼光看问题,这句话我觉得很有道理,因为你会发现这些悲观主义者,大多数是以静态的观点来看待问题。我举一个具体的例子,有一些悲观主义者会觉得,现在大模型算力消耗太大了,以后无以为继,这就是一种静态的观点。如果是以动态发展的眼光去看,那你的思路就是未来一定会有新型的能源出现,有可能是更绿色,或者说更高效的,我们一定会发展出新的办法去解决新的问题,而不是说问题层出不穷,我们的能力就定格在现在这个节点了,然后一筹莫展,充满悲观。我们还是希望办法总比问题多。
有在座的各位,尤其在开源领域,大家都一起合作,三个诸葛亮难道——不,是三个臭皮匠——等等,万一我们三个都是诸葛亮呢,那不更厉害了,还干不过一个司马懿吗?哈哈。所以我觉得所谓开放封闭的讨论,背后最核心的其实是这种发展观和静止观的 PK。我是更偏向于发展观的,我们还是希望技术要往前走,办法总比困难多,人类一定会发展出更新的技术去解决这些新的困难,当然新的技术又会产生新的问题,那就再用新的技术再去解决。
这两个路线的共存,我觉得还是比较正常的。当然它会影响到很多,包括政策制定者,尤其是美国政策制定者的相关法案的出台。

加州正在审议中的法案 SB1047,该法案旨在规范前沿人工智能模型的开发和使用,例如要求开发者在训练前满足特定安全要求,并进行合规性审计等。来源:leginfo.legislature.ca.gov
加州最近出了一个 Senate Bill,包括欧盟的法案,这些法案的特点是什么呢?就是非要人为地设置一个门槛,这个门槛要么是训练模型所用的算力,要么是训练模型用的预算(budget),它非要设一个门槛,高于这个门槛就必须要接受管制,必须要汇报,或者是不能再开放,等等。这背后就是我们刚才说的 AI 悲观主义者,很多都是他们在驱动的,他们会觉得大模型如果超过了他们现在设的这个门槛,就会变得太危险了。
但是真正从业者,大家都会吐槽,AI 是有 Scaling Law 的,法案今天写的这个门槛,过三个月可能就成为一个家家户户都能实现的技术,因为通过法案是需要时间的,一般要辩论好长时间,等真正落地了,最后变成大家谁都不能做了。然后看中国这边,热火朝天地出来一堆东西。所以我觉得这确实是我们的优势,或者说是他们的一个短板。
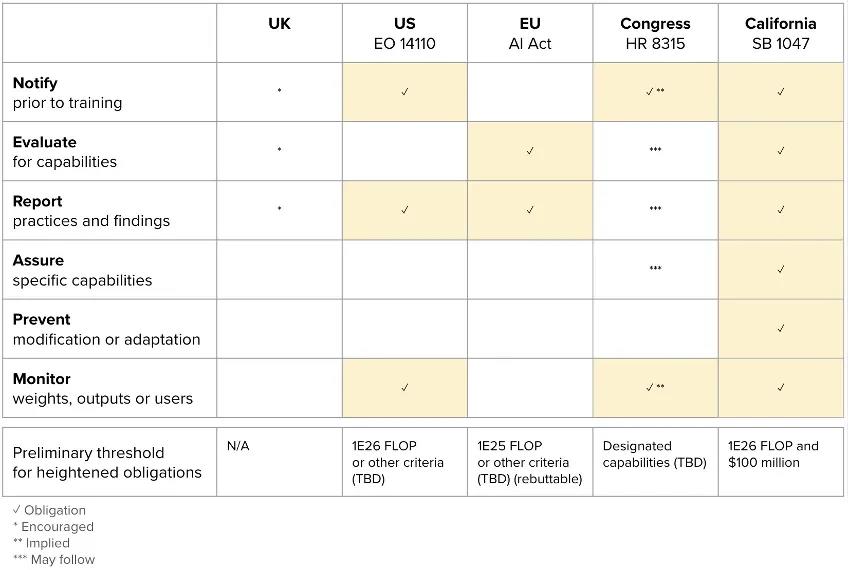
英国、美国、欧盟和美国(包括前述加州法案 SB1047)针对前沿人工智能模型的监管措施对照,用勾号、星号和 N/A 表示是否强制要求、鼓励或暗示采取相应的监管措施,包括对模型权重和计算能力 (FLOP) 的要求。来源:Stability AI 公共政策专家 Ben Brooks@opensauceAI,他曾在 GoogleX、Uber 和 Coinbase 等公司工作。
机器之心:正好也谈到这里了,您认为中美 AI 开源生态之间最主要的差异是什么?
黄之鹏:我觉得美国或者说北美,一个确实比我们做得好的地方,是它的产业生态协作非常成熟。我之前就一直在讲一个例子,叫 Nous Research,是一个特别有趣的团体。其实是一帮草根,很多人之前根本没有接触过 AI,都是从零学的。但就是这样意气相投的一帮人,他们最早是想做同人文的生成。
那时候哪有大厂干这件事?于是他们首先自己整理了数据集,整理了很多二次元的角色,后来加入了更多对话的结果,现在这个数据集迭代了很多轮,成为开源圈里非常重要的一个数据集,叫 Nous-Hermes。
草根没有算力,但至少在北美,能够获取免费算力的渠道非常多,比如可以去找 Together Networks,可以去找很多公有云,总有一些免费的算力可以使用。因为产业分工比较成熟,所以每一个新产业刚形成的时候,它骨子里这种协作的意识就会出来。哪怕在英伟达的卡刚开始紧俏的时候,也有很多人在提供免费算力。他们的想法是,我既然有,就可以共享出来。
所以,Nous Research 这帮人有做数据集的,有免费算力协同的,有很多在算法上愿意跟他们合作的,还有的完全就是因为开源而加入其中。最后形成了一个,他们给自己起名字叫 Nous Research,一开始都不是一个实体,后来变成了一家初创公司,然后拿到了投资。我觉得他们这个个案是一个特别好的例子,就是你可以在这样一种产业环境中,从零自己长起来,因为有很多人都在帮你。但不是说刻意在帮你,是因为大家知道,我在这个产业里面,我能做这些,我是予取予求的,我能贡献这些,我自己也是有收益的。你免费用我的算力,你一旦用多了,很多人都会知道这里的算力基础设施很不错,是 Nous Research 一直在用的,这就是一个长效的价值,人家看得很清楚。包括帮着做算法创新的,短期的热情一定是有长期回报的,那么长期的回报是什么?就是我这个产业逐渐成熟之后,所有在这个产业里的人都有长期的回报。
我觉得这一点确实是北美更成熟,相比之下,国内还可以再做得更好一些,整个产业层内的协作,比如说学校之间能不能有更好的学术的,比如基于开源的协作,我们确实有提升空间的。
机器之心:最后一个问题,接下来中国的 AI 开源生态有哪些值得关注的趋势?
黄之鹏:我觉得先不说 AI,中国整个的开源生态,这20年发展还是挺大的,包括核心从业者对开源的理解,开源本身该怎么做,进步真的很大。回到人工智能,美国那些持封闭论的人没有看清楚的一个问题是,如今 AI 的本质就是数据。我们国家数据太丰富了,所以首先可供我们研究的基础,模型的输入是绝对有保证的,而这会带来一个必然的结果,就是我们研发出的模型肯定是有保证的,而且多样性一定非常好。这个基本盘决定后,我们现在看到一个还算是相当热闹,或者说繁荣的中国 AI 开源生态。
如果说缺的,就是刚才分析中美 AI 开源生态的对比,我们的产业协同如果能做得更好一些,不管是国家牵头还是产业自发的,多做一些跨烟囱的协同性工作,我觉得以后会发展得更好,因为这意味着产业生态的土壤会越来越厚,大有可为。
嘉宾简介
黄之鹏,AI 开源生态专家,现任 LFAI Data 基金会董事,致力于推动全球化 AI 开源生态协作。毕业于加州大学尔湾分校,研究方向为网络协议优化。研究兴趣包括大模型相关技术、零知识加密技术、生物科技、通用计算领域相关技术等。
黄之鹏先生在开源领域和电信标准领域皆拥有超过15年的丰富经验。在云计算时代,他深度参与了 OpenStack 社区,并联合英特尔、红帽等公司,主导发起异构计算通用管理框架 Cyborg 项目。他还参与了云原生基金会 CNCF 社区,并与谷歌、红帽、微软等公司共同发起了 Kubernetes 策略工作组。此外,他还牵头创立了软件定义存储开源社区 OpenSDS(现更名为 SODA)。
近年来,他专注于 AI 开源社区的运营管理,包括 MindSpore、ONNX、Kubeflow 等 AI 开源项目以及 openEuler、openGauss 等操作系统及数据库开源项目,对 AI 开源生态发展趋势有着深刻理解,并在 IEEE ICC、CCF ADL Workshop 以及 CCCF 期刊发表过相关研究成果。
更新于:4个月前