脸叔空难剧定档;《羊毛战记》新季震撼回归
2024-10-17 18:48
科林·费尔斯(Colin Firth)领衔的有限新剧《洛克比空难事件》(Lockerbie)揭开先导预告,明年1月2日开播。
该剧会聚焦1988年12月泛美航空103航班在苏格兰小镇上空遇难的事件。

当时该航班在起飞38分钟后在洛克比上空爆炸,259名乘客和机组人员遇难,11名洛克比当地居民也在飞机坠毁时丧生。

费尔斯届时会饰演Jim Swire,他是一名英国医生,在这场悲剧中失去了女儿Flora。从那以后,他和妻子一起坚持不懈地追求正义。
在这场灾难之后,他被提名为英国受害者家属的发言人。
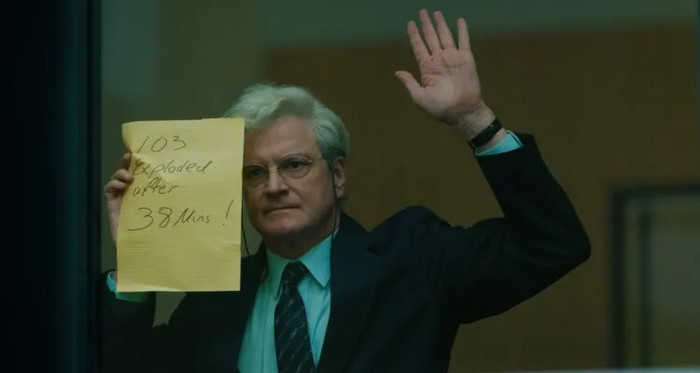
“跨越大洲和政治分歧,Jim 开始了一段无情的旅程,这不仅危及他的稳定、家庭和生活,而且也彻底推翻了他对司法系统的信任。

随着真相在其眼下发生变化,他对世界的看法也永远被玷污了......”


科幻悬疑剧《羊毛战记》(Silo)第2季预告震撼出炉,11月15日开始每周上线,大结局定于明年1月17日(共10集)。
剧集运作人格雷厄姆·约斯特(Graham Yost)在谈及新一季时透露,“这一季会由两条故事线。有 Juliette的故事,然后还有筒仓的”。

预告一方面展现了Juliette的现状,另一方面则是在运量中的反抗,而后者显然不是Bernard 最害怕看到的。



相关资讯
羊毛月不是知道错了,他是知道自己要完了
羊毛月为什么要道歉?他是知道自己说错话了吗?有个网友的评价太对了:他不是知道错了,他是知道自己要完了。为什么这么说?因为在了解羊毛月后就能知道,在他的创作里,“蹭”是没有错的,“阴阳怪气”就是风格。咱们先来说说“蹭”。大学生找工作难,是不是讨论度较高的话题?是..
三天掉粉百万,整顿不了职场的00后,开始整顿羊毛月
大家好,我是公子。“何不食肉糜”,在羊毛月身上体现得淋漓尽致。羊毛月是坐拥800万粉丝的网红,出生北京,从小到大都在北京读书,高中走艺术上的中传,后保研去了北大,借着学历光环走红,和已经翻车的猫一杯炒CP。而在猫一杯塌房后,他果断删掉合拍视频,没受到什么牵连,继续..
“肖申克”蒂姆·罗宾斯加盟新剧《羊毛记》
据Variety网站获悉,蒂姆·罗宾斯(Tim Robbins)已经和休·豪威担任编剧的《羊毛记》(Wool)改编剧签约。该剧由莫滕·泰杜姆(Morten Tyldum)执导。罗宾斯将与之前宣布的演员丽贝卡·弗格森(Rebecca Ferguson)一起出演,丽贝卡在《碟中谍5》中出演女主。《羊毛记》讲述在已经..
让我们化身侦探,来一场《空难解密》
MH370航班失事时间虽已过去多年,但仍然在人们的记忆中占据着一个牢靠的角落。如今只要看到与飞机失事有关的新闻或者相关题材的影视剧,你的第一记忆点就是马航。很多人会觉得飞机出事概率很高,特别前对于空难的报导更加深人们对于飞机失事的恐惧感,严重的患上恐飞症也不是稀罕..
科幻动作片《明日战记》百度云资源「bd1024p1080pMp4粤语中字」云网盘下载
香港男星古天乐是许多影迷的偶像,而除了幕前演出以外,他也担任了电影制作人一角,不过由他亲自监制以及主演的科幻动作片《明日战记》近日上映后,疑似因为票房不理想,让他忍不住在镜头前落泪。据了解,《明日战记》是末日科幻动作片,由古天乐、刘青云、刘嘉玲、姜皓文与谢君豪..
“企鹅人”为谋权以暴制暴;《羊毛战记》新季定档
《新蝙蝠侠》(The Batman)衍生剧《企鹅人》(The Penguin)新款预告重磅登场,9月19日HBO电视首播。视频中,大家会看到科林·法瑞尔(Colin Farrell)饰演的Oz(外号“企鹅人”)在犯罪猖獗的哥谭市街头以暴制暴的方式谋取权力,然而他的面前有不少挑战,其中包括从阿卡姆疯人院..
Netflix发布空难悬案MH370的纪录片预告
2014年马航MH370航班失踪事件引起全球关注,一架载有 239 人的飞机莫名消失。雷达探测不到任何踪迹,黑匣子也一直未找到,至今似乎也没有一个明确的结论。“九年之后,我们依旧不知道发生了什么、是谁造成的…”Netflix推出关于该空难的纪录片剧集《MH370:消失的航班》,将于3月8..
《行尸走肉》衍生剧定档,玛姬尼根成搭档~你准备入坑吗?
《行尸走肉》衍生剧《死亡之城》(Dead City)定档6月19日开播,第一季一共6集!杰弗里·迪恩·摩根劳伦·科汉回归饰演尼根和玛姬,他们将一起前往曼哈顿,一座早已被丧尸占据的城市,营救玛姬被绑架的儿子赫谢尔。衍生剧将具有与母剧不同的感觉,因为它从佐治亚州的树林等转移到..
空难幸存者被鲨鱼包围,灾难片《无路可逃》发布正式预告
当一架飞机在太平洋坠毁并搁置在海底峡谷的边缘,被困的幸存者们需要与时间赛跑,因为他们不仅面临着被淹死还有成为鲨鱼盘中餐的危险。
《绝境盟约》曝海报,空难幸存者不得已之下采取极端生存方式
电影《绝境盟约》是根据真实事件改编而成的。根据1972年发生的安第斯空难,影片讲述了一支橄榄球队乘坐乌拉圭空军571号航班飞往智利途中遭遇的灾难。飞机在安第斯山脉中心的冰川上坠毁,45名乘客中只有29人幸存。面对世界上最险恶的环境之一,幸存者们被迫采取了极端措施来保全生..
《国王的演讲》男主领衔真实空难剧
奥斯卡奖获得者科林·费尔斯(Colin Firth)确认主演有限新剧《洛克比空难事件》(Lockerbie),它会聚焦1988年12月泛美航空103航班在苏格兰小镇上空遇难的事件。当时泛美航空103航班在起飞38分钟后在洛克比上空爆炸,259名乘客和机组人员遇难,11名洛克比当地居民也在飞机坠毁时..
羊毛战记第一季好看吗?(第一集着实太惊艳,只要不烂尾,这就是一部难得一见的神剧)
终于又盼来一部惊艳非凡的科幻悬疑剧集,一看便追到停不下来,看了第一集就被惊艳到,引人入胜的剧情太诱人。这部新剧就是《羊毛战记》,共计10集,由丽贝卡弗格森、大卫奥伊罗、蒂姆罗宾斯、科曼、拉什达琼斯、哈丽特瓦尔特、阿维纳什等主演,演员阵容豪华。根据休豪伊的同名畅销..