
PixelPlayer:能自动从视频中识别和分离不同的声音源
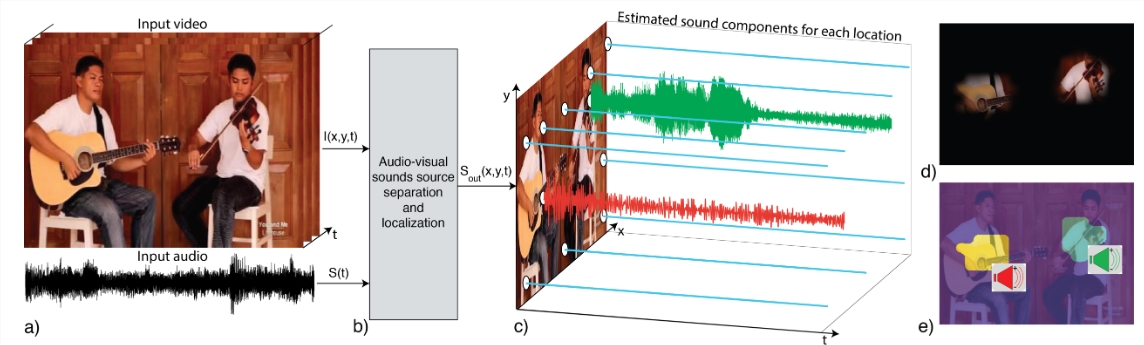
PixelPlayer是MIT研究团队开发的项目,能够自动从视频中识别和分离出不同的声音源,并与画面位置匹配。这种能力使得系统能够识别视频中的不同声音来源,如不同乐器的声音,分别提取和分离这些声音源的声音,而无需人工标注数据。
项目地址:https://top.aibase.com/tool/pixelplayer
PixelPlayer的核心功能包括声音源分离、声音定位和多声音源处理。通过分析视频,系统能够将声音信号分离成多个组件,每个组件对应于视频中的一个特定区域,例如将视频中的人声、乐器声等分离成独立的音轨。除了分离声音,PixelPlayer还能够定位声音的来源,即确定视频中哪个区域产生了特定的声音,并能够分别识别和处理多个声音源同时发出声音。
工作原理方面,PixelPlayer系统的训练使用了大量视频,而无需提供关于视频中存在哪些乐器、它们的位置或声音的信息。通过观看未标记视频,系统自我学习理解声音和图像之间的关系,实现声音源的分离和定位。系统通过声音和图像的联合分析,为视频中的每个像素分配一个声音成分,实现声音的精确定位和分离,识别视频中的哪些区域正在产生声音,并将声音分解成代表每个区域声音的组件。
应用场景包括音视频源分离、声音定位、AI内容配音、自动字幕和描述生成、音频可视化、音乐教学和学习、以及研究和开发。通过PixelPlayer,音频工程师和制作人可以从复杂的音频录制中分离出单独的乐器声轨,进行更精细的音频处理和混音。在增强现实和虚拟现实应用中,系统可以逼真地模拟声音来源,极大增强用户体验。此外,PixelPlayer还可以帮助内容创作者为视觉内容配音,提高视频内容的可访问性,创造新颖的音乐可视化体验,以及展示不同乐器在合奏中的声音分布和特点。
MIT研究团队通过PixelPlayer项目不仅推动了音视频处理技术的边界,还为多模态人工智能研究和应用提供了新的视角和工具。
更新于:10个月前