
AI2发布开放语言模型OLMo 号称多项性能媲美Llama2
**划重点:**
1. ???? AI2发布了开放语言模型(OLMo),该框架旨在促进大规模语言模型的研究和实验,通过在Hugging Face和GitHub上提供训练代码、模型和评估代码来实现。
2. ???? OLMo的首批模型包括7B规模的四个变体和1B规模的一个模型,涵盖不同的架构、优化器和训练硬件,旨在满足多样化的研究需求。
3. ???? 该项目的目标是建立全球最好的开放语言模型,已经启动不同规模、模态、数据集、安全措施和评估等方面的工作。
AI2最新发布的开放语言模型(OLMo)框架旨在推动大规模语言模型的研究和实验。通过在Hugging Face和GitHub上提供训练代码、模型和评估代码,AI2致力于让学术界和研究人员能够共同研究语言模型的科学,探索新的预训练数据子集对下游性能的影响,以及研究新的预训练方法和稳定性。

该项目的首批模型包括四个7B规模的最终变体,对应不同的架构、优化器和训练硬件,以及一个1B规模的模型,所有模型均在至少2T令牌上进行了训练。这是一个长期计划的第一步,计划继续发布更大规模的模型、经过指导调整的模型以及更多变体。
每个模型都提供完整的训练数据,包括生成训练数据的代码,以及用于分析预训练数据的AI2的Dolma和WIMBD。此外,还提供了完整的模型权重、训练代码、训练日志、以Weights Biases日志形式呈现的训练指标,以及推理代码。每个模型的训练过程中的500多个检查点也可在HuggingFace上作为修订版本获得。
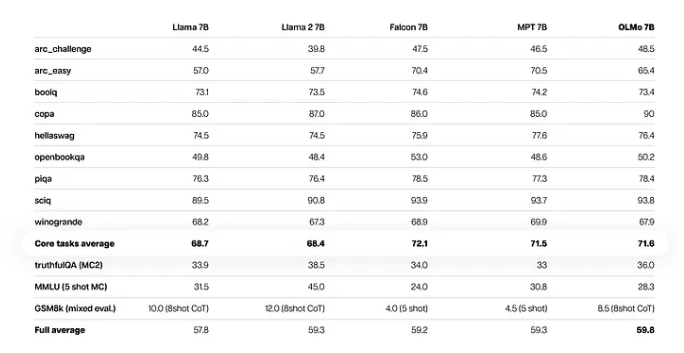
在创建强大的开放模型时,AI2从许多其他开放和部分开放的模型中吸取了经验,并将它们作为OLMo的竞争基准。该项目的技术报告提到,OLMo7B模型在诸如生成任务或阅读理解(如truthfulQA)等方面超过了Llama2,但在流行的问答任务(如MMLU或Big-bench Hard)上略显落后。
对于1B OLMo模型,使用AI2的Paloma和可在GitHub上获得的检查点进行了分析,以探讨模型在语言预测和模型规模等因素之间的关系。AI2强调Paloma的方法试图通过均匀采样各个领域,更平衡地表示使用语言模型的众多领域。
OLMo框架采用了最新文献中的许多趋势,包括不使用偏见(如PaLM中的稳定性)、PaLM和Llama使用的SwiGLU激活函数、Rotary位置嵌入(RoPE)以及GPT-NeoX-20B的BPE基础标记器的修改版本,旨在减少个人可识别信息。
该发布仅是OLMo和框架的开端,未来计划推出不同规模、模态、数据集、安全措施和评估等方面的工作。AI2鼓励使用OLMo模型,提供了简便的安装步骤和使用示例,并表示未来将推出指导调整的模型、完整的训练日志和wandb报告等功能。
博客网址:https://blog.allenai.org/olmo-open-language-model-87ccfc95f58
项目入口:https://top.aibase.com/tool/olmo
更新于:10个月前