
谷歌被打脸!Gemini Pro被证实和GPT3.5差距不大
要点:
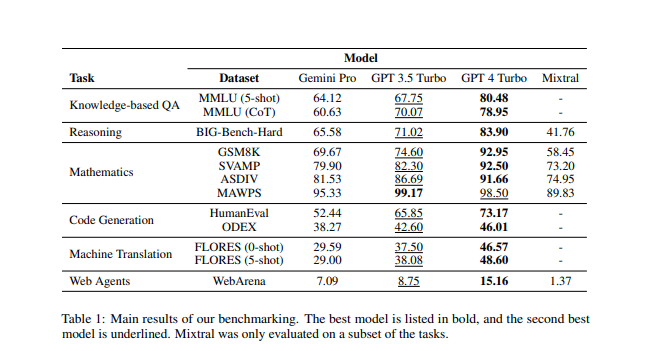
在CMU的研究中,Gemini Pro被与GPT-3.5和Mistral8×7B进行了深入的比较,结果显示GPT-3.5在多个任务上几乎全面优于Gemini Pro,但差距不大。
通过测试任务包括基于知识的问答、通用推理、数学问题、代码生成等领域,Gemini Pro在某些任务上表现较差,但在特定任务中超越了GPT-3.5。
文章强调Gemini Pro是多模态的,通过视频、文本和图像训练,而GPT-3.5Turbo和GPT-4Turbo主要基于文本,Mixtral是开源竞争对手。
谷歌最新发布的Gemini Pro自发布以来备受瞩目,谷歌声称其优于GPT-3.5。然而,CMU的研究通过深入的实验对比,展示了GPT-3.5在多个任务上的全面优势。Gemini Pro虽然在某些任务上稍显不足,但整体表现与GPT-3.5相近,为大模型领域的竞争增添了新的火花。
论文地址:https://arxiv.org/pdf/2312.11444.pdf
研究涉及了基于知识的问答、通用推理、数学问题、代码生成等多个领域。在基于知识的问答任务中,Gemini Pro在一些子任务上落后于GPT-3.5,尤其在多选题答案输出中显示了一定的偏见。通用推理测试中,Gemini Pro的精度略低于GPT-3.5Turbo,尤其在处理较长、复杂问题时表现不佳,而GPT-4Turbo则表现更为稳健。
数学问题领域的测试包括小学数学基准、稳健推理能力、不同语言模式和问题类型等。Gemini Pro在某些任务上略显不足,特别是在多样化的语言模式任务中,表现较GPT-3.5Turbo稍逊。在代码生成方面,Gemini Pro在两项任务上的表现均低于GPT-3.5Turbo,与GPT-4Turbo相比则差距更大。
总体而言,Gemini Pro作为多模态模型,尽管在某些任务上稍显不足,但在特定领域表现出色,超越了GPT-3.5。然而,在大多数测试中,GPT-3.5Turbo仍然保持领先地位,证明其在开源模型中的卓越性能。这一研究为科技领域的大模型竞争提供了客观中立的第三方对比,为未来的模型发展提供了有益的参考。
更新于:11个月前