
腾讯AI实验室联合悉尼大学引入了GPT4Video 提升LLM的视频生成能力
要点:
1、GPT4Video是一个统一的多模型框架,使得大型语言模型具备视频理解和生成的能力。
2、GPT4Video提出了一种简单而有效的微调方法,以提高视频生成的安全性。
3、研究团队发布了数据集,以促进未来在多模态LLMs领域的研究。
最近在多模态大型语言模型(MLLMs)领域取得了显著进展,但在多模态内容生成方面仍存在明显的空白。为了填补这一空白,腾讯AI实验室和悉尼大学的合作引入了GPT4Video,这是一个统一的多模型框架,使得大型语言模型具备了视频理解和生成的独特能力。
GPT4Video的主要贡献可以总结如下:引入了GPT4Video,这是一个丰富LLMs能力的多功能框架,既可以进行视频理解,又可以进行生成;提出了一种简单而有效的微调方法,旨在提高视频生成的安全性,为常用的RLHF方法提供了一种吸引人的替代方案;发布了数据集,以促进未来在多模态LLMs领域的研究。
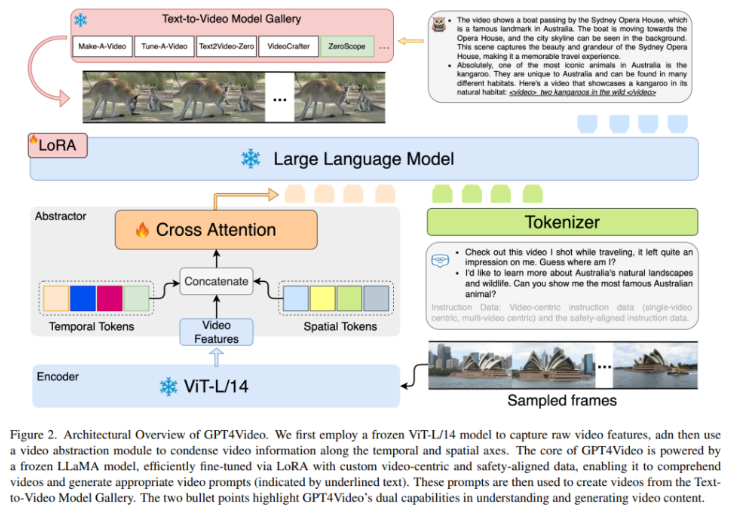
GPT4Video是对现有多模态大型语言模型(MLLMs)的局限性的回应,尽管这些模型擅长处理多模态输入,但在生成多模态输出方面存在不足。GPT4Video的架构包括三个重要组件:视频理解模块,利用视频特征提取器和视频摘要器在LLM的词嵌入空间中对视频信息进行编码和对齐。
LLM的基本结构,包括词嵌入器、多头自注意力机制和前馈神经网络,用于处理文本信息;视频生成模块,利用视频特征提取器和视频解码器从LLM的词嵌入空间中生成视频;安全微调方法,通过引入安全性目标和生成器的控制策略,提高视频生成的安全性。
GPT4Video的引入填补了多模态内容生成领域的空白,并且提供了一种统一的多模型框架,使得大型语言模型具备了视频理解和生成的能力。该研究还提出了一种简单而有效的微调方法,并发布了数据集,为未来的多模态LLMs研究提供了便利。
更新于:2023-12-07 13:21