
田渊栋团队最新论文解决大模型部署难题 推理系统吞吐量提高近30倍!
田渊栋团队最新发表的论文解决了大型语言模型在实际部署中遇到的内存和输入长度限制的问题,将推理系统的吞吐量提高了近30倍。论文提出了一种实现KV缓存的新方法,通过识别和保留重要的tokens,显著减少了内存占用,并在长输入序列的任务中表现良好。
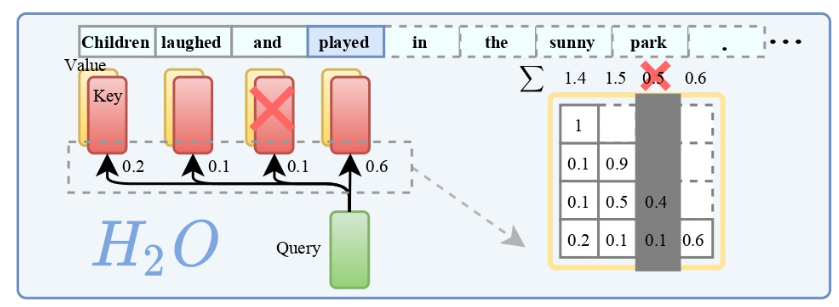
这篇论文的研究对象是大型语言模型(LLM),该模型在实际部署中面临着KV缓存成本昂贵和对长序列的泛化能力差的问题。为了解决这些问题,田渊栋团队提出了一种基于重要tokens的KV缓存逐出策略,通过识别并保留对生成结果有重要贡献的tokens,显著减少了内存占用,并提高了模型在处理长输入序列时的表现。
论文地址:https://arxiv.org/pdf/2306.14048.pdf
代码地址:https://github.com/FMInference/H2O
在实验中,作者使用了OPT、LLaMA和GPT-NeoX等模型验证了他们提出的方法的准确性和有效性。实验结果显示,通过使用该方法,DeepSpeed Zero-Inference、Hugging Face Accelerate和FlexGen这三个推理系统的吞吐量分别提高了29倍、29倍和3倍,且在相同的批量大小下,延迟最多可以减少1.9倍。
通过研究发现,大部分注意力键和值嵌入在生成过程中贡献较少的价值,只有一小部分tokens贡献了大部分的价值。基于这个发现,作者提出了一种基于重要tokens的KV缓存逐出策略,动态保持最近的tokens和重要tokens的平衡。通过使用这种策略,可以显著减少KV缓存的大小,从而降低了内存占用,并提高了模型的推理效率。
综上所述,田渊栋团队的最新论文成功解决了大型语言模型在实际部署中的难题,通过优化KV缓存的实现方法,将推理系统的吞吐量提高了近30倍。这一成果在NeurIPS23上将进行展示,对于大型语言模型的部署和应用具有重要的意义。
更新于:2023-12-07 13:10