
华人团队推出Medusa简单框架 可将LLM推理速度提高2倍
2023-09-13 13:13
来自普林斯顿、UIUC等机构的华人团队提出一个用于加速大型语言模型(LLM)推理速度的简单框架Medusa,并于9月12日开源发布。测试结果显示,Medusa可以将LLM的生成效率提高约2倍。
Medusa是一个简单的框架,它让大家也可以使用多解码头技术来加速大型语言模型的生成。目前,许多热门的加速技术如speculative decoding都存在一些痛点,比如需要一个不错的draft模型作为基础,系统复杂度高,采样生成时效率不高等。
项目地址:https://github.com/FasterDecoding/Medusa
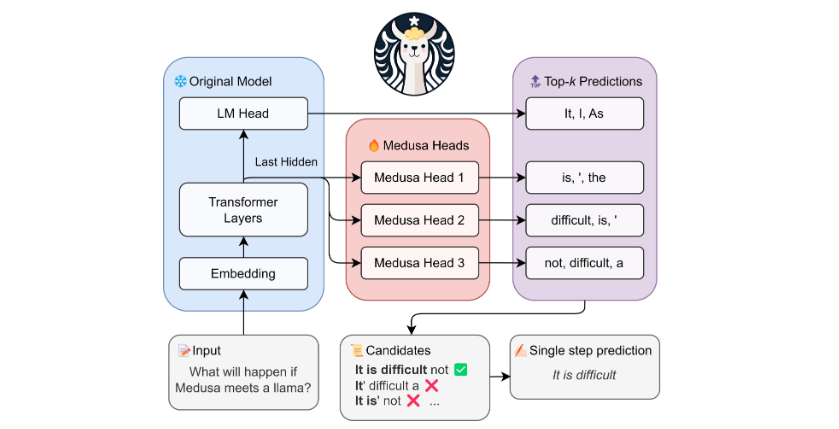
Medusa的方法是在原有的语言模型上增加额外的“解码头”,让每个头同时预测多个可能的未来词元。在使用Medusa增强模型时,原有的模型保持不变,仅新增的解码头在训练中进行微调。生成时,这些头并行产生多个可能的词,然后通过一种基于树的attention机制合并处理,最后使用一般的采纳策略从候选中挑选出最长的可信前缀进行解码。
研究人员通过以下几点设计,来解决speculative decoding存在的问题:
1) 不引入新的模型,仅在原模型上新增解码头,训练时参数效率高。
2) 生成时不需要严格匹配原模型的分布,使非贪婪生成甚至比贪婪解码还快。
第一个版本主要优化了每个batch只有一个样例的场景,也就是本地机器上常见的使用方式。在这种配置下,Medusa可以为Vicuna系列模型带来约2倍的加速。研究人员称正在积极扩展Medusa的应用场景,集成到更多的推理框架中,以获得更高的性能提升。
Medusa核心功能:
- 在现有语言模型上增加多解码头
- 高效训练参数
- 生成时树形attention机制合并多个预测
- 非贪婪生成模式下实现更快速度
更新于:2023-09-13 13:13