《西部世界》S03E01:被人工智能绑架的世界
HBO推出的美剧《西部世界》,在前两季播出的时候就因为烧脑的剧情和深刻的主题,引起了观众的热烈讨论。
在经历了第二季异常复杂的时间线之后,最近回归的第三季改变了叙事手法,比之前更加容易理解了。
已经播出的首集整体观感比较爽,赛博朋克风格的建筑、女主德妹从颜值到武力的全面开挂、《绝命毒师》“小粉”亚伦·保尔的惊艳亮相......诸多元素的结合让观众对本季充满了期待。

“Free will is not free”(自由意志并不自由),本季的主题围绕海报上的这句话展开。
所谓的自由意志,是否只是一种错觉?
在剧中所展现的那个现实世界里,人类的生活被智能系统操控,试图掌握自己命运的接待员恰恰是人工智能的产物。
因此,无论是人类还是接待员,本质上都是被科技裹挟的存在。如此看来本季《西部世界》的中心思想,似乎和《黑镜》不谋而合。
【温馨提示:以下有剧透】

从园区来到人类世界的德妹,正按部就班执行自己的复仇计划。
上季在园区熔炉系统的图书馆里,德妹曾拿起一本游客的代码书籍观看,想必这便是「动悉」(Incite)公司已经退休的那位技术高管的个人资料了。
这位富豪居住在中国北海的小岛上,得知提洛公司园区发生接待员造反杀人事件之后,他决定将手上持有的股份卖掉却遭到无情拒绝。
德妹轻松入侵了富豪家中的系统,进入别墅里拿走了钱财和机密文件,还顺便让他因为曾经的所作所为付出了应有的代价。
此处展现的情节颇具讽刺意味,人类一边想要成为支配性的物种,一边又被自己创造出来的科技产品所支配。
这么一看,人类似乎是在作茧自缚。人工智能虽然给生活带来了便利,但是也隐藏着安全隐患,稍不留神就会迎来毁灭。

德妹之后赶往伦敦,解锁了一秒换装的新技能,瞬间变身上流社会的名媛。
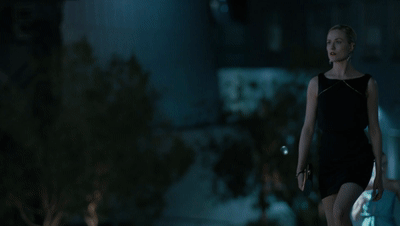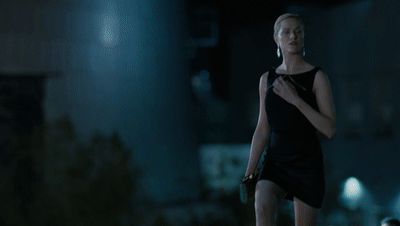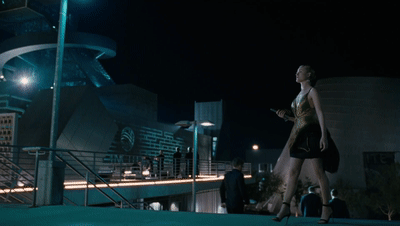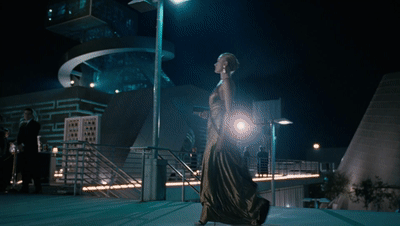
她此次的目标是接近「动悉」(Incite)创始人的儿子利亚姆,套取更多关于该公司创造的罗波安系统的秘密。

然而利亚姆只是一个傀儡,在父亲去世之后他就被限制进入系统内部,甚至不知道这个系统到底在做什么。
拥有控制系统权限的,是一个名叫塞拉克的男人。

德妹最后干掉了利亚姆身边的保镖男,并制造出了和保镖一模一样的接待员,准备让其打进科技公司内部。这个接待员体内究竟是谁的意识,目前尚不清楚。
“你们本来是自由的,你们没有崇拜的神,但你们却想造一个神,但是你们创造出来的不是神,真正的神要降临了,他们怒火中烧。”
德妹的这句话照应了本集的标题《求主宽恕》(Parce Domine),一旦德妹掌控了罗波安系统,那么人类可能会因此付出惨痛的代价。
原本自由的人类创造了人工智能,本以为能够过上更好的生活,却不知不觉被罗波安系统剥夺了自由选择的权利。
正如利亚姆的朋友所说的那样,人类其实和接待员一样都被系统操控,不过那些勇于反抗现实的接待员,至少活得比人类有尊严。

《绝命毒师》“小粉”饰演的卡莱布,出场画面和第一季时的德妹十分相似,可见是主创别有用心的安排。

这是否在暗示卡莱布的接待员身份?他此时是否和当初的德妹一样,遵循固定的剧本套路,处于即将自我觉醒的状态?

有的情节看起来也是比较蹊跷,比如卡莱布提到他不是第一次被人拿枪指着,也不是第一次被人爆头,难道意味着他曾经死过一次了?还有就是卡莱布的母亲说他并不是自己的儿子。

这些细节或许只是一个烟雾弹,目前尚不清楚卡莱布的真实身份。
我更倾向于认为他是人类,卡莱布这条故事线展现了一个普通社畜的生活日常,从中能感受到那种被人工智能支配的恐惧。

剧中的那个人类现实世界,推行着一种英才管理制度,由罗波安系统指导人类做出正确的选择,为每个人分配合适的工作。

卡莱布白天做着系统安排的建筑工作,不断用心灵鸡汤麻醉自己:
“我只需要更努力地工作,继续提高我的分数,看看有没有更好的出路。”
然而这份工作只是勉强糊口罢了,并不足以支付母亲的医疗费用。

他不得不通过一款手机应用,在晚上完成指定的任务赚钱。

比起贫穷窘迫的生活,心理上的创伤似乎对他的打击更大。
他有过当兵服役的经历,自从亲眼目睹好友弗朗西斯去世之后,他便患上了PTSD,一直都对此难以释怀。
卡莱布通过和人工智能聊天来接受心理治疗,这个人工智能可以模仿他死去的战友。

“他们把这个世界打造成一场游戏,然后他们作弊,确保他们永远会赢。”
“你说系统根本就不在乎我们,他们根本不在乎我们的死活。”
卡莱布身为社会底层民众,开始重新审视自己所在的世界。
他发现自己并没有在一个自由的环境里,而是置身于一个被暗箱操纵的游戏规则当中。
早已被智能系统绑架的他,如同行尸走肉一般,在虚假的世界里负重前行。

人工智能并没有让卡莱布过上好日子,反而使他对这个世界多了一丝无奈和绝望。
在人工智能提供的对话服务里,毫无真情实感只有冰冷的程序规则。
于是卡莱布决定拒绝AI提供的心理治疗,转而去寻找一些真实的东西。

或许一切都是命中注定,他之后偏偏遇见了受伤的德妹。

此情此景让人联想到第一季里,年轻的威廉也曾这样抱着德妹。

可以预测卡莱布同样会是一个对德妹产生深远影响的男人,他或许可以改变德妹对于人类的态度和看法。
(PS.大明湖畔的泰迪怕是不服:大家都是以同样的姿势怜香惜玉,凭什么我不配拥有提名?)

德妹套取科技公司系统情报的同时,也在利用夏洛特的身份渗透进提洛公司高层。
这个夏洛特如今已经不是原来的那个人了,我们尚不清楚呆在夏洛特体内的究竟是谁的意识。

夏洛特作为提洛公司的临时执行总裁,在位于旧金山的总部和诸位高层召开了会议。
有人建议关闭主题乐园,毕竟园区发生的接待员暴动事件,可是导致了113人丧生,其中大部分都是董事会成员和乐园的工作人员。

夏洛特并没有听从董事会高层的提议,而是坚持运营公司园区,并且认定伯纳德为此次事故的真凶。

伯纳德成了被追捕通缉的乐园杀手,他从阿诺德家里离开之后,就化名德尔加多·阿曼德在一家工厂当屠夫。

他做了多次测试进行自我诊断,查看自己是否被别人控制从而丧失自我。
他最后一次联系德妹是在92天之前,由此可以判断距离上次见面(也就是第二季末在阿诺德家里发生的事情),已经过去了三个多月的时间。

被别人认出了逃犯身份之后,伯纳德瞬间切换成战斗模式,成功化解了危机。

重新进入正常模式的伯纳德,决定离开此地回到西部世界园区。

从下集预告可以看出,伯纳德在园区见到了安保小哥斯塔布斯。他们两人意图寻找梅芙,想要联合起来阻止德妹毁灭人类的行动。

通过片尾彩蛋,我们得知苏醒之后的梅芙,正处于纳粹统治之下的二战时期。
继西部乐园、幕府世界、印度园区之后,提洛公司旗下又有一个主题乐园——战争园区露出了真容。

梅芙还见到了幕后大佬塞拉克(文森特·卡索饰演),他就是德妹一直寻找的能够控制罗波安系统的人。
塞拉克似乎想要说服梅芙去对付德妹,由此可以猜测持有不同理念的德妹和梅芙,她们两个接待员之间终将会有一番较量。

在上季结尾德妹带着五个接待员的意识球逃离了园区,我们只知道其中一个是伯纳德,并不清楚剩下四个究竟是谁的意识。

有观众通过预告里德妹和夏洛特在床上拥抱的姿势,猜测夏洛特的身体里有泰迪的意识。
梅芙似乎也在推测德妹身边的接待员,其中有一个是泰迪。
在上季最后,泰迪明明是被传送到了那个美好的虚拟世界。不过,德妹带他来到人类世界的可能性虽然比较小,但也并不能完全排除这种情况。

从浴缸里惊醒的老年威廉,想必终会经历专属于他的噩梦,不知道这次他又会和德妹上演怎样的爱恨情仇?

本季估计会涉及到更多关于自由意志的话题,剧中人类世界的底层社畜,每天上班下班吃饭睡觉,日复一日在固定的模式里生存,本质其实和园区里那些重复循环故事线的接待员差不多。
他们以为生活在自由的环境里,殊不知自己早已被人工智能绑架。

福特在前两季说过很多颇有内涵的话语,其中有一句探讨自由的台词引人深思:
“真正自由的东西,需要能够质疑其基本动力,去改变它们。”
当德妹计划借助人工智能控制人类之时,卡莱布已经开始质疑智能系统本身。
或许他们在未来将会改变世界,一起奔向真正的自由。
【阅读更多关于《西部世界》的文章,欢迎关注我的个人公众号:晶姐札记】

相关资讯
《追杀华金穆列塔》百度云网盘下载.阿里云盘.西班牙语中字.(2023)
类型: 动作 / 西部制片国家/地区: 墨西哥资源下载:追杀华金穆列塔阿里云盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘下载更新日期:2023-02-22语言: 西班牙语首播: 2023-02-17(墨西哥)季数: 1集数: 8单集片长: 35IMDb: tt15383758剧情简介:Fo..
《朽木 第一季~第三季》百度云网盘下载.1080P下载.英语中字.(2004)
又名: 死木 第一季 / 枯镇 第一季 / 朽木 / 无法无天(港) / 化外国度(台)资源下载:朽木 第一季~第三季网盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘下载更新日期:2022-08-24导演: 沃尔特 希尔 / 戴维斯 古根海姆 / 阿兰 泰勒 / 艾德 比安奇 ..
《寿喜烧西部片》百度云网盘夸克下载.阿里云盘.中字.(2007)
导演: 三池崇史又名: 日式牛仔一品鍋 / 日式火锅 / 源平斗——西部风云 / Sukiyaki Western Django资源下载:寿喜烧西部片下载阿里云盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘编剧: 三池崇史 / 中村雅主演: 伊藤英明 / 安藤政信 ..
2018年西部剧情《落难女子》BD中英双字幕
[落难女子][BD-mkv.720p.中英双字][2018年西部剧情] ◎译 名 落难女子 ◎片 名 Damsel ◎年 代 2018 ◎产 地 美国 ◎类 别 剧情/喜剧/西部 ◎语 言 英语 ◎字 幕 中英双字幕 ◎上映日期 2018-01-23(圣丹斯电影节)/2018-06-22(美国) ◎IMDb评分 5.7/10 from 697 users ◎豆瓣评分 5..
2018年剧情传记《女先行者》BD中英双字幕
[女先行者][BD-mkv.720p.中英双字][2018年剧情传记] ◎译 名 女先行者 ◎片 名 Woman Walks Ahead ◎年 代 2017 ◎产 地 美国 ◎类 别 剧情/传记/历史/西部 ◎语 言 英语 ◎字 幕 中英双字幕 ◎上映日期 2017-09-10(多伦多电影节)/2018-06-29(美国) ◎IMDb评分 6.1/10 from 1,110 ..
《恐怖草原》百度云网盘下载.1080P下载.英语中字.(2022)
导演: 麦克 鲍力施 Michael Polish编剧: Josiah Nelson资源下载:恐怖草原网盘,百度云盘,下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘下载主演: 吉娜 卡拉诺类型: 西部制片国家/地区: 美国语言: 英语 English上映日期: 2022-06-14(美国网络)片长: 107分钟IMDb:..
《最后的受害者》百度云网盘下载.1080P下载.英语中字.(2021)
导演: Naveen A. Chathapuram又名: 最后的受害者资源下载:最后的受害者网盘,百度云盘,下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘下载编剧: Ashley James Louis / Naveen A. Chathapuram / Doc Justin主演: Ali Larter / Ron Perlman / Ralph Ineson类型: 动..
《勾魂树》百度云网盘夸克下载.阿里云盘.中字.(1959)
导演: 德尔默 戴夫斯 / 卡尔 莫尔登编剧: 多萝西 M 约翰逊 / 温德尔 梅斯资源下载:勾魂树下载阿里云盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘主演: 加里 库珀 / 玛丽亚 雪儿 / 卡尔 莫尔登 / 乔治 C 斯科特类型: 剧情 / 爱情 / 西部制片国..
《和平饭店》百度云网盘下载[MP4/mkv]蓝光[BD720P/HD1080P]UC网盘(1995)
导演: 韦家辉编剧: 韦家辉资源类型:老板的故事百度云网盘 在线观看 迅雷下载主演: 周润发 / 叶童 / 秦豪 / 刘洵 / 吴倩莲 / 刘晓彤 / 李兆基 / 鲁芬类型: 动作 / 西部制片国家/地区: 中国香港语言: 粤语上映日期: 1995-04-12片长: 89 分钟又名: 老板的故事 / The Peace Hotel / P..
《西部世界1-3季》百度云网盘下载.阿里BD1080P.英语中字.(2016)
又名: 西方极乐园资源类型:西部世界第二季第一季第三季网盘線上看,百度网盘,迅雷磁力电驴ed2k下载,百度云盘,mp4/mkv导演: 乔纳森 诺兰 / 强尼 坎贝尔 / 理查德 J 刘易斯 / 米歇尔 麦克拉伦 / 尼尔 马歇尔 / 文森佐 纳塔利 / 弗雷德 托耶 / 斯蒂芬 威廉姆斯编剧: 乔纳森 诺兰 / 丽..
《百战宝枪》百度云网盘夸克下载.阿里云盘.中字.(1950)
导演: 安东尼 曼又名: 温彻斯特73年 / 无敌连环枪 / 西域神枪资源下载:百战宝枪下载阿里云盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘编剧: Robert L. Richards / 博登 蔡斯 / 斯图尔特 N 雷克主演: 詹姆斯 斯图尔特 / 谢利 温特斯 / 丹 德..
《无人区》百度云电影-在线观看-超清BD1080P|国语中字(2013)
导演: 宁浩编剧: 述平 / 邢爱娜 / 崔斯韦 / 王红卫 / 尚可 / 宁浩资源类型:无人区百度云网盘 在线观看 迅雷下载主演: 徐峥 / 黄渤 / 余男 / 多布杰 / 王双宝 / 巴多 / 杨新鸣 / 郭虹 / 陶虹 / 黄精一 / 赵虎 / 王辉类型: 剧情 / 犯罪 / 西部制片国家/地区: 中国大陆语言: 汉语普..
最新单机游戏《闪电十一人3:面向世界的挑战》硬盘版
中文名称: 闪电十一人3:面向世界的挑战游戏类型: 模拟游戏游戏语言: 简体中文游戏大小: 339.76 MB游戏简介: 《闪电十一人3:面向世界的挑战 The 王牙》除了原有的“面向世界的挑战篇”外,还将会追加全新的故事,来自80年后未来的敌人与雷门十一人展开了新的激烈战斗,..
《江湖女间谍》百度云网盘夸克下载.阿里云盘.中字.(1965)
导演: 路易 马勒编剧: 路易 马勒 / 让-克劳德 卡里埃尔又名: 万岁玛利亚 / 玛丽娅万岁资源下载:江湖女间谍下载阿里云盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘主演: 碧姬 芭铎 / 让娜 莫罗 / 乔治 汉密尔顿 / 波莱特 杜博斯特 / Gregor vo..
2018年西部剧情《去日无痕》BD中英双字幕
去日无痕][BD-mkv.720p.中英双字][2018年西部剧情] ◎译 名 去日无痕/消失的日子/日子一去不复返/日子一去不返 ◎片 名 Gone Are the Days ◎年 代 2016 ◎产 地 美国 ◎类 别 西部/剧情 ◎字 幕 中英双字幕 ◎上映日期 2018-03-16(美国) ◎IMDb评分 4.9/10 from 154 users ◎文件..
2018年西部动作《敌对分子/敌对者》BD中英双字幕
敌对分子/敌对者][BD-mkv.720p.中英双字][2018年西部动作] ◎译 名 敌对分子/敌对者 ◎片 名 Hostiles ◎年 代 2017 ◎产 地 美国 ◎类 别 剧情/西部/冒险/动作 ◎语 言 英语/夏安语 ◎字 幕 中英双字幕 ◎上映日期 2017-09-02(特柳赖德电影节)/2018-01-26(美国) ◎IMDb评分 7.3/1..
《甜蜜的复仇》百度云网盘下载[MP4/mkv]蓝光[BD720P/HD1080P]UC网盘(2013)
导演: 罗根 米勒编剧: 罗根 米勒 / 诺亚 米勒 / Andrew McKenzie资源类型:甜蜜的复仇百度云网盘 在线观看 迅雷下载主演: 艾德 哈里斯 / 詹纽瑞 琼斯 / 詹森 艾萨克 / 爱德华多 诺列加 / 斯蒂芬 鲁特 / 杰森 阿尔丁 / 迪兰 科宁类型: 西部制片国家/地区: 美国语言: 英语上映日期: ..
《淘金记》电影百度云下载 在线观看 BD1080P 英语中字(1925)
导演: 查理 卓别林编剧: 查理 卓别林资源类型:淘金记百度云网盘 在线观看 迅雷下载主演: 查理 卓别林 / 马克 斯旺 / Tom Murray / 亨利 伯格曼 / Malcolm Waite / 乔治亚 黑尔 / Jack Adams / Sam Allen / Harry Arras / 艾伯特 奥斯汀 / Marta Belfort / George Brock / 海尼 康..
《爱是永恒承诺》百度云网盘夸克下载.阿里云盘.中字.(2004)
导演: 小迈克尔 兰登又名: 爱的永恒诺言资源下载:爱是永恒承诺下载阿里云盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘编剧: Cindy Kelley / 小迈克尔 兰登主演: 凯瑟琳 海格尔 / 詹纽瑞 琼斯 / 罗根 巴塞洛缪类型: 剧情 / 家庭 / 西部制片国..
《西部风云》百度云网盘下载.阿里云盘.英语中字.(2005)
又名: 走进西部 / 西部风云史资源下载:西部风云网盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘下载更新日期:2022-09-23导演: 罗伯特 多恩海姆 / 塞尔吉奥 米米卡-戈赞编剧: Craig Storper / 赛勒斯 诺拉斯特 / Kirk Ellis主演: 西蒙 本克 / ..
2017年剧情悬疑《雨和闪电的气息》BD中英双字幕
雨和闪电的气息][BD-mkv.720p.中英双字][2017年剧情悬疑] ◎译 名 雨和闪电的气息 ◎片 名 The Scent of Rain & Lightning ◎年 代 2017 ◎产 地 美国 ◎类 别 剧情/西部/悬疑 ◎语 言 英语 ◎字 幕 中英双字幕 ◎IMDb评分 5.1/10 from 421 users ◎豆瓣评分 6.2/10 from 15 users..
《侠骨柔情》百度云网盘夸克下载.阿里云盘.中字.(1946)
导演: 约翰 福特又名: 大侠复仇记 / 三叉口 / 荒野大决斗资源下载:侠骨柔情下载阿里云盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘编剧: 萨姆 海尔曼 / 萨缪尔 G 恩格尔 / 斯图尔特 N 雷克主演: 亨利 方达 / 琳达 达内尔 / 维克多 迈彻 / 卡..
《孤鸽镇》百度云网盘下载.阿里下载.英语中字.(1989)
导演: 西蒙 温瑟又名: 寂寞之鸽资源下载:孤鸽镇网盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘下载更新日期:2022-10-03编剧: 拉里 麦克穆特瑞 / 威廉 D 威特利夫主演: 罗伯特 杜瓦尔 / 汤米 李 琼斯 / 丹尼 格洛弗 / 戴安 琳恩 / 罗伯特 乌立..
[ 韩剧 ]《辅佐官:改变世界的人们》
该剧是讲述在聚光灯背后操纵这个世界的真实政治玩家们的危险赌局,将描写指向权力顶点的超级辅佐官张泰俊的炙热的生存故事。李政宰饰演张泰俊,他是4选议员的首席辅佐官,他以第一名成绩毕业于警队,曾活跃在搜查前线,但为了拥有更大的权力而进入国会,是一个把不可能变成可能的..
《危情普什卡》百度云网盘下载.1080P下载.英语中字.(2022)
导演: Raj Singh Chaudhary编剧: Raj Singh Chaudhary / 阿努拉格 卡施亚普资源下载:危情普什卡网盘,百度云盘,危情普什卡下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘下载主演: 亚尼 卡普 / 法缇玛 萨那 纱卡 / 萨提许 卡素吉 / Harshvardhan Kapoor / Sanjay..
2017年西部动作《左撇子布朗之歌》BD中英双字幕
左撇子布朗之歌][BD-mkv.720p.中英双字][2017年西部动作] ◎译 名 左撇子布朗之歌 ◎片 名 The Ballad of Lefty Brown ◎年 代 2017 ◎产 地 美国 ◎类 别 西部/动作 ◎语 言 英语 ◎字 幕 中英双字幕 ◎上映日期 2017-03-17(西南偏南电影节)/2017-12-15(美国) ◎IMDb评分 6.2/10 ..
《西部世界第三季》百度云网盘下载[MP4/美剧/mkv]蓝光[BD720P/HD1080P]免费分享(2020)
导演: 乔纳森 诺兰 / 詹妮弗 盖辛格 / 理查德 J 刘易斯 / 保罗 卡梅隆 / 安娜 福斯特 / 阿曼达 马尔萨利斯 / 海伦 谢费编剧: 迈克尔 克莱顿 / 丽莎 乔伊 / 乔纳森 诺兰 / 吉娜 阿特沃特资源类型:西部世界第三季百度云网盘 在线观看 迅雷下载主演: 埃文 蕾切尔 伍德 / 坦迪 牛顿 /..
《黄石 第五季》百度云网盘下载.阿里下载.英语中字.(2022)
导演: 斯蒂芬 凯又名: 黄石公园 / 黄石之争资源下载:黄石 第五季网盘,百度云盘,夸克下载,阿里网盘,迅雷网盘,百度网盘,mp4磁力电驴ed2k,百度云115网盘下载更新日期:2022-11-14官网:www.rrdyw.net/编剧: 泰勒 谢里丹主演: 凯文 科斯特纳 / 卢克 葛莱姆斯 / 凯利 蕾莉 / 韦斯 本特..
《女先行者》百度云网盘电影|在线观看uc网盘|蓝光超清BD1080P|中字(2017)
导演: 苏珊娜 怀特编剧: 斯蒂文 奈特资源类型:女先行者百度云网盘主演: 杰西卡 查斯坦 / 路易莎 克劳瑟 / 布兹 萨瑟兰德 / 查斯科 斯宾塞 / 塞伦 希德 / 金德尔 查特斯 / 山姆 洛克威尔类型: 剧情 / 传记 / 历史 / 西部制片国家/地区: 美国语言: 英语上映日期: 2017-09-10(多伦多..
韩影深度探索:五部伦理剧情片,解锁成人世界的多维画卷
各位影迷小伙伴们!新春佳节将至,是不是想在轻松愉快的氛围中,找几部好电影来深度品味一番呢?🎉 今天,我特地为你们精选了五部韩国伦理剧情佳作,它们不仅剧情扣人心弦,而且每一帧画面都蕴含着深刻的人生哲理,带你领略成人世界的多维画卷。(文末有惊喜)🎬首先,咱们聊聊《..