
GPT-5只会更笨!斯坦福莱斯研究警告,AI训AI超过5次,模型反噬,性能大减
用AI生成的数据训练AI,不会有魔法,只会被反噬。
近日,莱斯大学和斯坦福团队发现,将AI生成的内容喂给模型,只会导致性能下降。
研究人员对此给出一种解释,叫做「模型自噬障碍」(MAD)。

论文地址:https://arxiv.org/abs/2307.01850
研究发现在使用AI数据,经过第5次迭代训练后,模型就会患上MAD。66
在合成数据上训练AI模型会逐渐放大伪影
换句话说,如果不能给模型提供「新鲜的数据」,即由人类标注的数据,其输出质量将会受到严重影响。
拒绝模型「内耗」
目前,MAD尚未确认会影响所有AI模型,不过研究人员已经对自编码器、高斯混合模型、大语言模型进行了验证。
作者写道,「世界正在奔向一个未来,生成式AI的爆发,导致了互联网上的合成数据,很快就会超过真实数据。」
因此,当前的AI模型,正在不知不觉中接受越来越多的人工智能合成数据的训练。
比如,目前已知且开源的最大规模多模态数据集LAION-5B,已经用于训练当前最先进的文本-图像模型,包括Stable Diffusion。
这个数据集就包含了,从早期生成模型中采样的合成图像。
合成数据受欢迎的主要原因在于4点:
- 合成训练数据比获取真实世界的样本更容易、更快、更便宜
- 某种情况下,合成数据增强可以提高AI系统的性能
- 可以在医学成像或医疗记录等敏感应用中保护隐私
- 最重要一点,随着深度学习模型参数越来越庞大,现几乎没有真实数据可用了
为了获取更多真实数据,就连OpenAI近日与美联社签订协议,双方将共享部分新闻内容和技术。
但是,不管是有意,还是无意使用合成数据,已经背离了标准的AI训练实践:
一代又一代地重复这一过程形成了一个自噬循环(autophagous loop),也就是自耗(self-consuming)。
不同的自噬环变化取决于,现有的真实数据和合成数据如何组合到未来的训练集中。
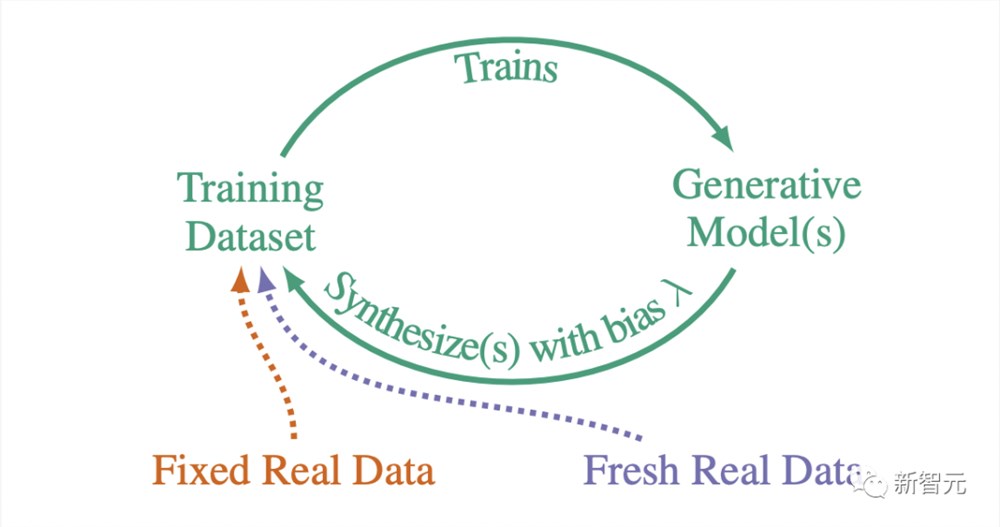
然而,根据合成数据的生成方式,还会出现其他变化。
比如,研究者或算法通常会通过手动「挑选」合成数据来引入采样偏差,以权衡感知质量(即图像/文本看起来来不错)与多样性(不同类型图像/文本)。
研究者介绍,「质量」和「多样性」两个非正式概念,分别与精确度和召回率的统计指标密切相关。
如果合成数据已经存在于我们今天的训练数据集中,那么自噬循环在未来几乎是不可避免的。
那么影响究竟有多大?
研究人员表示,无论训练集的组成,或采样方法如何,自噬循环对生成模型的属性和性能的潜在影响仍知之甚少。
而有一点可以确定的是,使用合成数据重复训练可能会,逐渐放大任何生成模型中存在的偏差和伪影。
总之,这项研究有三个重要贡献:
1. 自噬循环的真实模型
团队研究了自噬循环的3种变体:完全合成循环,其中生成模型仅在前几代的合成样本上进行训练;合成增强循环,其中训练集还包括一组固定的真实数据;新数据循环,其中训练集还包括每一代的一组新的真实数据。
所有这3种自噬循环模型的底线是,如果每一代没有足够的新鲜真实数据,未来的生成模型注定会MAD。
2. 采样偏差在自噬循环中起着关键作用
模型实践者倾向于手动挑选合成数据,更喜欢高质量的样本,并删除低质量的样本。此外,最先进的生成模型通常具有可控参数,可以以牺牲多样性为代价来提高合成质量。
研究证明,通过这种质量多样性(精确召回)权衡引起的采样偏差,对自噬训练循环的行为有重大影响。
具体来讲,在没有采样偏差的情况下,自噬会导致质量和多样性的快速下降,而在采样偏差的情况下,质量可以保持,但多样性下降得更快。
3. 自噬循环行为适用于各种生成模型和数据集
除了对简单多元高斯和高斯混合模型的分析和实证研究之外,团队还在正文和附录中,证明了主要结论适用于各种生成模型。
部分实验结果
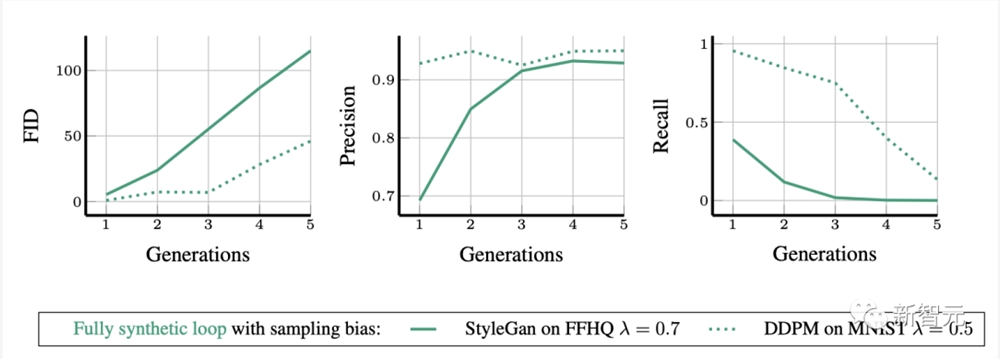
在没有采样偏差的全合成循环中,完全使用合成数据训练生成模型,其合成数据的质量和多样性都会逐代下降。
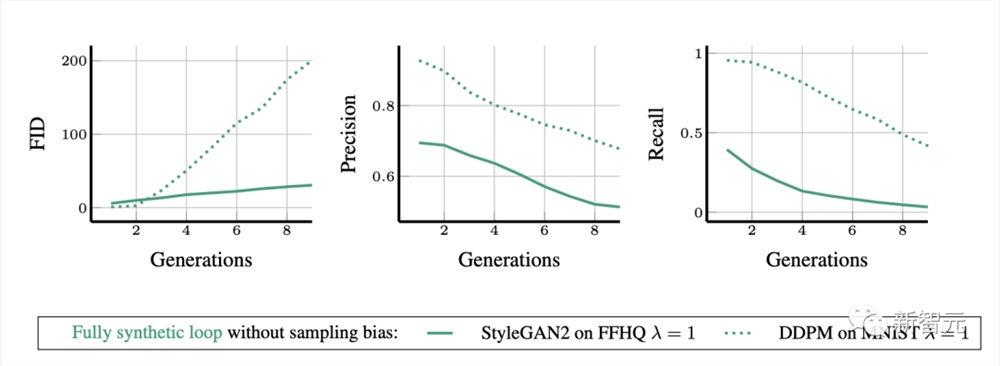
在全合成循环中,生成的合成FFHQ和MNIST图像的FID、精度和多样性(召回率)
研究者给出了MNIST的真实数据和合成数据的t-SNE图,这些数据来自没有采样偏差的全合成环路(λ =1)。
可以看到,生成的模式逐渐合并,相互之间失去了分离。到第10代,生成的样本几乎无法辨认。
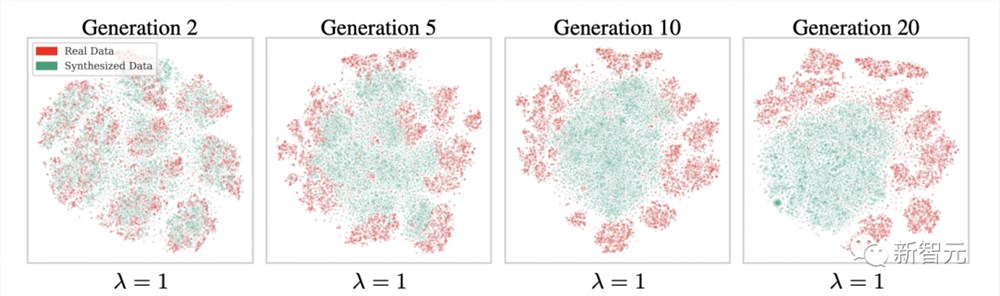
在没有采样偏差的情况下,合成数据模型会偏离真实模型并合并
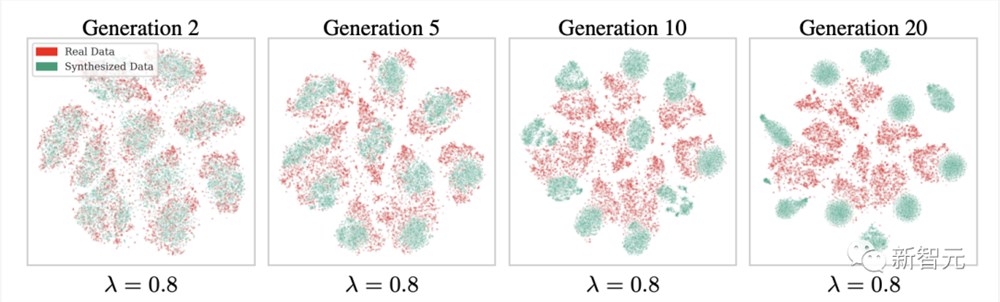
研究还发现,提高合成质量会损害合成多样性。
在高质量合成数据上训练生成模型总是会导致合成质量或合成多样性的损失
由于采样偏差,合成数据模型会围绕单个(高质量)图像偏移和崩溃,而不是合并。
给生成数据打水印
所有这些会出现MAD症状的模型都已经广泛应用,并运行一段时间了:
自编码器可以处理诸如流行预测(例如社交媒体应用程序的算法)、图像压缩、图像去噪和图像生成等任务;
高斯混合模型用于密度估计、聚类和图像分割等目的,在统计学和数据科学中特别有用。
如今流行的 ChatBot, 其应用的大型语言模型(如ChatGPT,和Anthropic的Claude)使用自己生成的内容进行训练时,也容易在训练中出现MAD现象。
同时,这些也强调了这些AI系统在我们生活中的重要性:算法人工智能模型在企业和公共领域都得到了广泛应用。
这项研究提供了一种窥探「AI技术黑箱」的方法。
但也粉碎了我们从某些AI模型中制造一个「仓鼠轮」的希望:将数据输入模型,然后将其自身生成的数据再次输入模型,产生更多的数据再反馈进模型的过程。
反而这种训练方式会对当前存在的模型,以及这些模型的应用造成威胁。
如果一个已经商业化使用的模型事实上是通过对其自身的输出进行训练的,那么该模型很可能已经向其平均值回归(记住,这需要大约5个输入输出周期才能显现)。
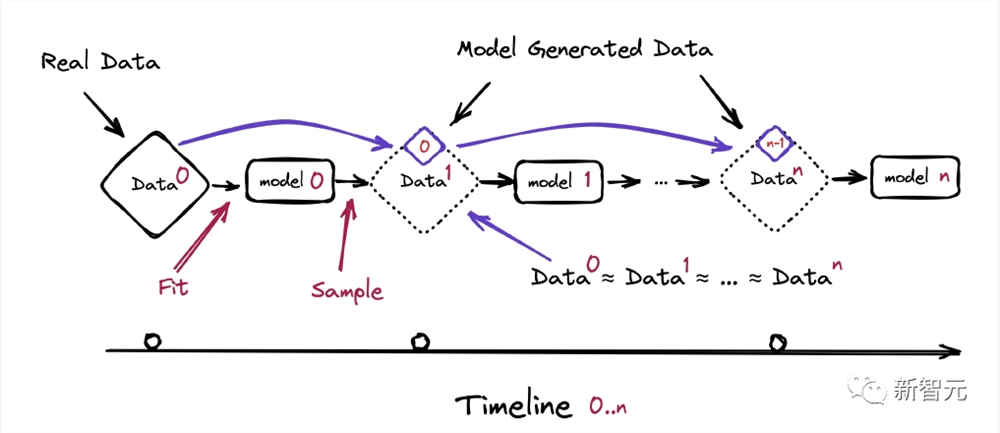
模型崩溃过程示意图
如果该模型向其平均值回归,那么它在某种程度上已经存在着偏见,因为它没有考虑到本应属于少数派的数据。这也可以称之为算法上的偏见。
研究结果中得出的另一个重要观点是对数据来源的关注。现在更加重要的是能够将「原始」数据与「人工」数据区分开来。
如果无法确定哪些数据是由LLM或生成图像应用程序创建的,可能会不小心将其包含在下一代产品的训练数据中。
不幸的是,这个问题很可能已经无法挽回:这些类型的网络已经产生了大量未标记的数据,并被纳入其他系统中。
即使我们在ChatGPT或Midjourney的爆发之前拥有整个互联网的快照,但长期以来AI生成的数据每天都在大量涌入全球网络,更别说它们运行时产生的巨量数据。
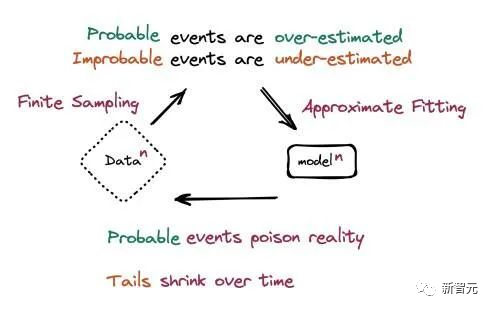
模型崩溃成因的示意图
但即便如此,至少我们已经知道了这一点。
知道这一点,意味着寻找一种可以识别AI生成内容的水印(这是绝对正确的)已经成为一项更为重要和更有利可图的工作,标记AI生成数据的责任也变得更为严肃。
除此之外,还有其他方法可以弥补这些偏差。
其中一种方法是简单改变模型的权重:增加分布尾部的结果的相关性或频率,它们将自然地沿着钟形曲线移动,靠近均值。这意味着它们就不太容易被修剪掉,从而避免了自动生成训练中的数据丧失。
模型仍然会丢失曲线边缘的数据,但这些数据不再是唯一的数据来源了。
但是,权重是如何决定的?权重应该如何调整?频率应该增加多少?
此外,我们也有责任了解模型微调的影响、以及这些影响的后果如何影响模型最终的生成内容。
以上每个问题的回答都会引发一系列其他问题的关注:
与模型回答背后的真实性相关的问题(其中偏差被称为幻觉);
模型是否存在偏见,以及这种偏见的根源(如果是来自训练数据本身或用于创建网络的权重过程,现在我们也从MAD过程中了解到了);
当模型训练自己的数据时会发生什么.....但如我们所看到的,最后结果并不理想。
同样地,这个问题也是不可忽视的:
就像不接触新知识的人会越来越固步自封和偏执。这与「模型在自己生成的内容上训练时,它会崩溃」是相同的道理。
参考资料:
https://arxiv.org/pdf/2307.01850.pdf
https://futurism.com/ai-trained-ai-generated-data
更新于:2023-07-23 14:17