
李彦宏:大模型即将改变世界,百度要第一个把全部产品用大模型重做一遍
这就是站在技术浪潮的最前沿,李彦宏的最新感悟。
在今天的2023中关村论坛上,李彦宏作为开场嘉宾,发表了题为《大模型改变世界》的演讲。
这一国际科技大会由科技部、国家发展改革委、工业和信息化部、国务院国资委、中国科学院、中国工程院、中国科协、北京市政府共同主办。演讲嘉宾包括微软创始人比尔·盖茨,以及菲尔兹奖得主、图灵奖得主等顶级科学家代表。
规格之高,不消多说。而微软和百度,又是如今大洋两岸最受关注的引领大模型变革的科技公司,双方创始人同台演讲,早已引发不少关注。
不过,相比于技术本身的“卷”,科技领袖们的着眼点,更加本质。
比如,大模型成为焦点的实质是什么——
大模型成功地压缩了人类对于整个世界的认知,让我们看到了实现通用人工智能的路径。
李彦宏如是分析。
并且,在更为深刻地影响世界之前,AI本身已经因大模型的出现而改变。
处在以大模型为核心的人工智能新起点,现实应用的构建逻辑也已经到了转变的时刻:
用大模型重做产品,“不是整合,不是接入,而是重做,重构”。
大模型改变人工智能,即将改变世界
为什么说大模型改变了人工智能,又即将改变世界?李彦宏给出了三方面的思考。
首先,是技术本身的突破。
第一个关键词,就是大算力+大模型+大数据,导致的智能涌现。
目前,业界的普遍认识是,500亿-600亿参数,是大模型是否具备涌现能力的一个门槛。
所谓智能涌现,简单说就是大模型让AI学会了“无师自通”,即便是此前没有接触过的任务,大模型也能hold得住。
举个例子,有用户发现,在要求ChatGPT扮演Linux终端来运行代码时,ChatGPT真的可以搞定这件事。而这种query在语言模型的训练阶段几乎不可能出现。
这彻底颠覆了过去AI应用的生产模式,使得AI流水线工厂取代“一事一模型”的AI手工作坊成为可能,使得AI应用的规模化落地成为可能。
与此同时,人工智能发展方向从辨别式走向生成式。
从数学模型上来说,辨别式模型关注的是不同类别的决策边界,而生成式模型则学习了数据的潜在特征,能通过理解每个类别的底层分布,来学习数据是如何生成的。

△图源LearnOpenCV
从实际案例来说,搜索引擎就是经典的辨别式AI。而文心一言这种会进行文学创作、写报告、画海报的,就是生成式AI。
生成式AI不仅使得人工智能更具“创造力”,更关键的是,它重新定义了人机交互:
对于人类而言,最自然的交流方式就是语言沟通。如果一句话就能让电脑帮你整理数据绘制图表,当然会比手动点开一大堆数据页面再逐个整理分析高效得多。
值得关注的是,大模型改变人工智能背后,底层的IT技术栈也发生了根本变化,即从芯片层(CPU为主)、操作系统层、应用层的三层架构,发展成为了四层架构:芯片层(GPU为主)+框架层+模型层+应用层。
这种IT架构的适配,正是“大力出奇迹”的基础,使得大算力、大模型、大数据能够三位一体,集中到一起打配合。
目前,无论是国外的微软、谷歌、亚马逊,还是国内的百度,都有从底层硬件到上层应用软硬一体的布局。
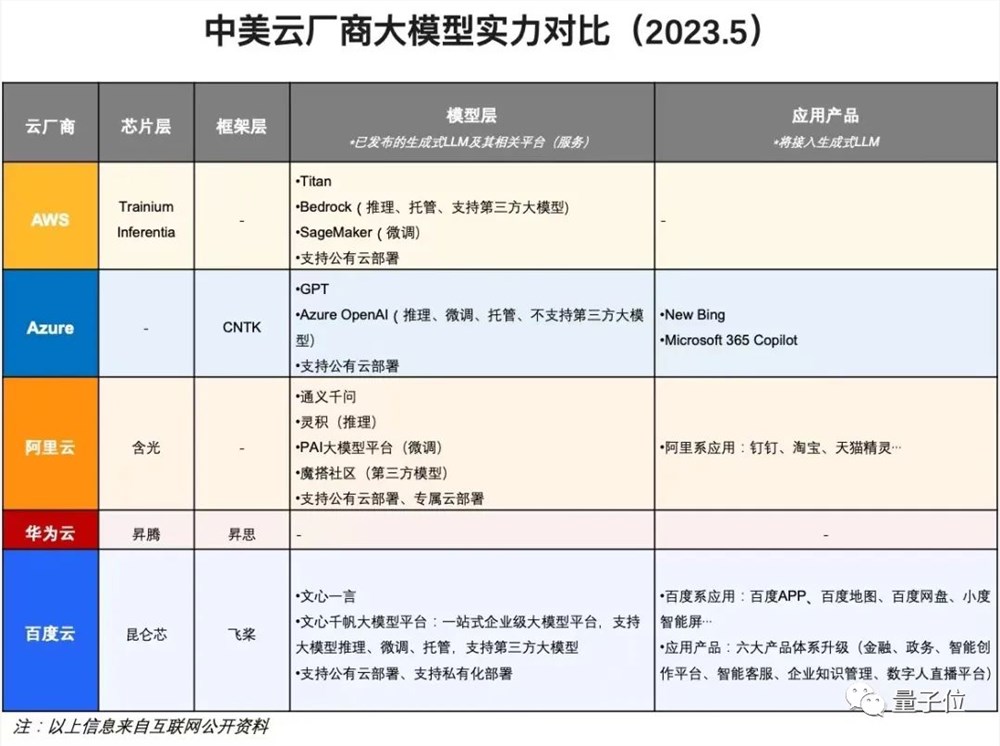
其中,只有百度是全球唯一全栈布局四层架构的公司。
其次,是产业需求的变化。
此前,李彦宏曾预测,大模型时代将产生三大产业机会,分别是:
新型云计算:其主流商业模式从IaaS变为MaaS。企业选择云厂商的关键因素,会从算力、存储等基础云服务,向框架、模型,以及模型、框架、芯片、应用四层之间的协同转变。
行业模型精调:通用大模型和企业之间的中间层,可以基于对行业的洞察,调用通用大模型能力,为行业客户提供解决方案。
基于大模型底座的应用开发
在这背后,需求侧的逻辑是,产业的需求在大模型的冲击下会发生改变,充分发挥大模型降本增效能力的AI原生思维将会影响所有产品、服务和工作流程。
那么,什么样的应用是AI原生应用?尽管还在探索的初期阶段,但大模型兴起以来,完全基于AI孵化出的创新产品已经崭露头角。
比如Jasper,一个通过AI帮助企业和个人写营销推广文案的应用。截至去年10月,Jasper估值已达15亿美元。
而AI绘画应用Midjourney,则已凭借订阅付费模式,在一年内实现了约1亿美元的营收。
李彦宏提到,百度内部的办公软件如流,现在也已基于文心一言,给每一位员工配备了一个具有丰富专业知识,能实时响应的工作助理。这个AI助理通过对话理解能力,可以实现对聊天记录的智能总结,在百度内部获得了一众好评。
李彦宏还强调:
百度要做第一个把全部产品重做一遍的公司,不是整合,不是接入,是重做,重构!
实际上,不止于百度,李彦宏认为,未来的趋势是所有应用都将基于大模型来开发。大模型最终深度融合到实体经济当中的具体体现,会是每个行业都有属于自己的大模型。
最后,是人们日常生活的改变。
大模型能快速破圈,成为街头巷尾人人讨论的话题,与其给个人带来的直观效率提升不无关系。
李彦宏引用研究机构的数据指出:未来10年,知识工作者的效率可以提升4倍。
这种效率提升,甚至会彻底改变人们的工作方式:
AI原生应用涌现之后,大量的工作交互最后都会编程提示词工程。
未来你的薪酬水平,将取决于你的提示词写得好不好,而不是取决于你的代码写得好不好。
李彦宏甚至大胆预测:10年后,全世界有50%的工作会是提示词工程,提出问题比解决问题更重要。
作为全球大模型竞逐中,国内最接近华山之巅的一号位,李彦宏的思考,亦是一份大模型落地征途中最具价值的参考答案。
事实上,以上三重思考,不仅停留在理论,百度本身已在躬身实践。
而另一方面,李彦宏放言“百度要做第一个把全部产品重做一遍的公司”,亦是行业大势之下,竞逐牌桌上话语权的决心体现。
百度为什么能做到?
百度发力大模型的更深层次原因,或许可以从行业现状和技术积累两个方面来解读。
首先是行业趋势。当下以大模型技术为代表的AIGC领域,已经开始从技术和应用两方面变革各行各业的生产方式,甚至带来突破性的效率提升。
根据量子位智库预测,AIGC市场规模会在2030年达到1.15万亿元,期间将经历培育摸索期、应用蓬勃期和整体加速期三个阶段。
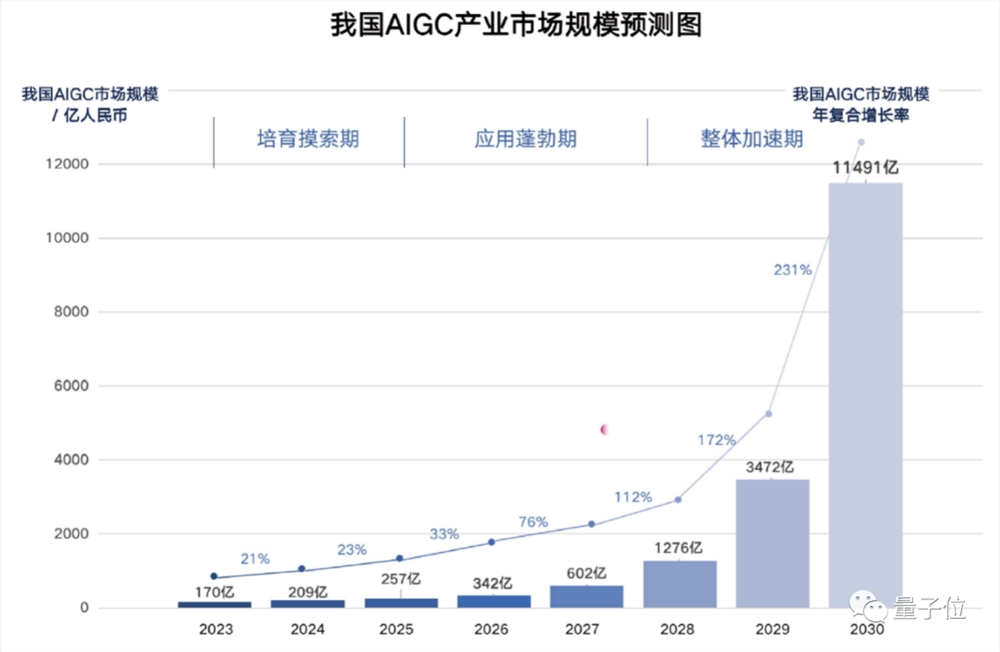
△来源于量子位智库
即使目前还在培育摸索期阶段,新玩家还在不断涌现,大模型头部领域的竞争却已经到了白热化阶段。
尤其行业中进展最快的技术玩家,已经开始有上层应用落地的趋势。
在国外,以OpenAI为例,根据SimilarWeb数据,ChatGPT仅2023年4月份,全球访问量就已经达到17.6亿次;至于与ChatGPT和GPT-3相关的应用,据gpt3demo统计已经超过800个,光是这两个月就增加了200多个。
在国内,百度也已经透露了大模型相关应用数据。文心一言开始企业内测之后,在与百度智能云接洽大模型业务的客户中,新客户比例已经超过老客户比例,有超过300+企业参与内测。
显然,当底层大模型技术达到稳定进入实际生产环节的水平,上层就会不断开发出真正有突破性质量的应用。
伴随着应用数量不断增加形成生态,最终将彻底在电商、内容、办公、交通等领域产生巨大的行业变革。
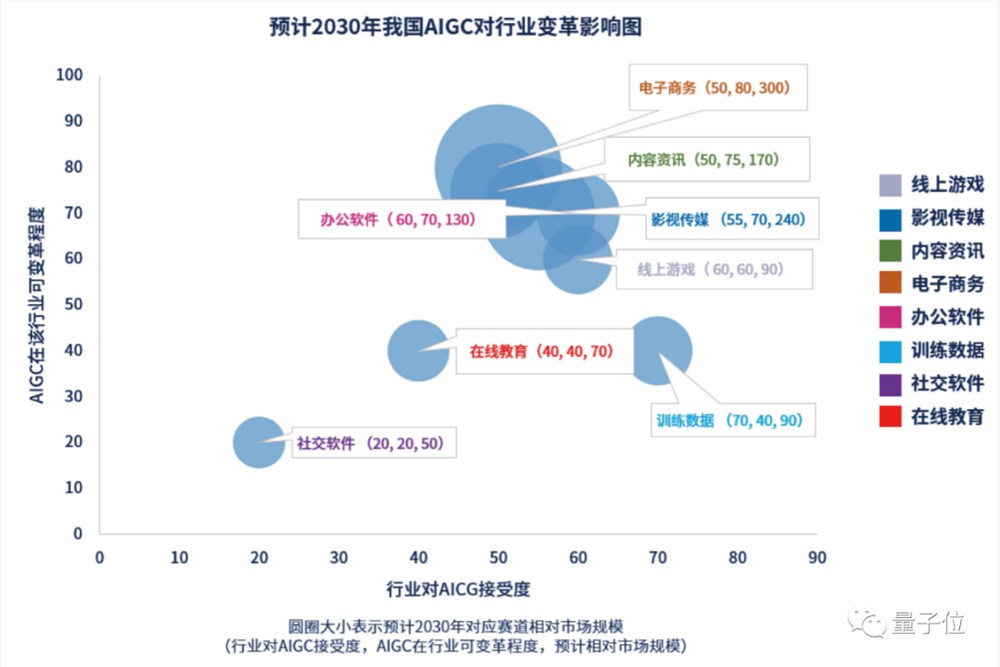
△来源于量子位智库
营销客服行业,百度文心一言目前已经将智能客服的知识生产效率提升了9倍,多轮对话构建的成本下降65%,终端用户认为客服接近真人的比率也在上升。
城市交通行业,目前北京亦庄的300多个路口,全都部署了百度AI信控系统,通过智能调整红绿灯的时间,提升最高30%的交通效率,有效解决了北京堵车这一“历史性难题”。
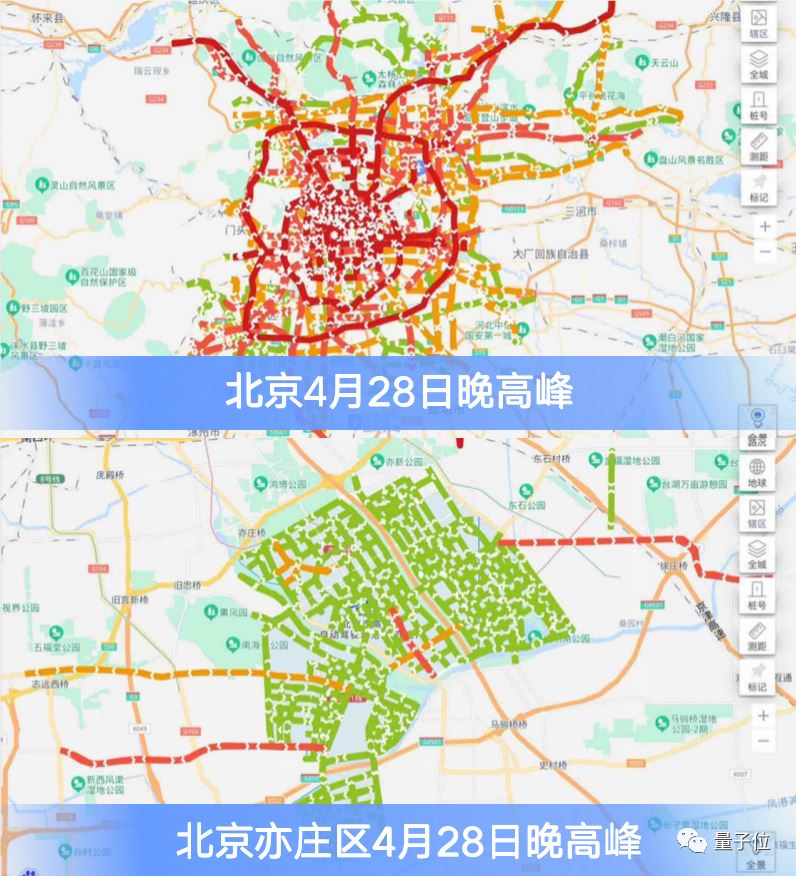
但若仅仅从行业变革的速率和市场规模角度出发,还无法完全解释百度发力大模型的原因。
毕竟从打造大模型的算力、数据和算法等层面的难度来看,仅凭短期的技术自研,显然难以支撑“快速重构所有产品”这一做法。
因此,从自身实力来看,百度这些年在自研芯片、架构到AI算法等各方面的“技术基底”,恰恰又成为了发力这波大模型浪潮必备的关键因素。
具体来说,主要可以分为三个方面。
其一,是在AI技术、尤其是大模型技术上的长期投入和积累。
最早从2013年开始,百度就在布局AI相关的技术,累计十年下来已经投入超过1000亿元,其中核心研发投入多个季度占比超过20%;
巨量研发投入背后,是技术护城河的建立,截至2022年4月,百度全球AI专利申请已经超过2.2万件。
这样的技术积累,让百度如今在大模型研发必不可少的芯片、框架、模型和应用四层架构中,均实现了对应的自研技术积累。
芯片层上,百度自研芯片昆仑二代,已经量产并部署了几万片,而昆仑芯最新的第三代,则预计2024年初投入量产;
框架层上,百度从2016年就开源了飞桨深度学习框架,目前这一框架已经集成了深度学习核心训练和推理框架、基础模型库、端到端开发套件等工具组件,在中国市场份额中排行第一;
模型层上,文心一言背后的核心技术文心大模型,从2019年开始就已经发布1.0版本,并在后续研发中不断进行优化,目前已经迭代到3.5版本;
应用层上,百度除了研发了单独的十个行业大模型以外,在搜索、智能云、自动驾驶、小度等上面也已经积累了不少研发经验。

不过,在各层技术栈上“单独发力”,还只是百度大模型的核心竞争力的一部分。
其二,针对这四层核心架构打出“组合拳”,又进一步形成了百度独特的技术优势。
虽然国外如亚马逊、国内阿里都已经在芯片层、模型层上发展了自研技术,微软则也已经在框架层和应用技术上有所准备。
但百度之所以同时发力自研芯片、框架、模型和应用领域,正是侧重于优化这些架构之间的高效协同,从而让自研大模型的基础设施能力进一步提升。
打个比方,对于大模型而言,想要极致优化推理速度和使用成本,算力、框架、模型、应用就像是四个齿轮,各自转速之外,很大程度上还要看它们之间的“配合能力”。
如今,这种“配合能力”,也已经成为百度发力大模型的独特优势。
打通四层技术架构后,百度已经能在基础设施层面上,打出千卡加速比90%、资源利用率70%,开发效率提升100%这样的“组合拳”。
如今,这一套组合拳更是在文心一言大模型应用的成本上,有直观的体现:
此前3月份启动内测时,如今不到2个月,百度大模型文心一言已完成4次技术版本升级,其推理成本更是已经降为原来的十分之一。
最后,在自主可控上,百度的这些技术不仅能用在自身大模型上,还能反过来进一步加速行业大模型的生产落地。
换而言之,文心一言不仅做到了数据可控、框架可控、模型可控,在全球科技领域中拥有话语权,更能将这一套技术对外输出,助力行业加速打造更多大模型。
以百度已经在内测的文心千帆大模型平台为例,仅需少量数据、最快几分钟,大模型就能完成一次“定制化”,极大地加速了大模型从研发到生产的全套过程。
而文心千帆的这一套流水线,并非仅为文心一言所打造,其训练调优经验和技术,已经可以向第三方输出。
换而言之,百度不仅是这波大模型变革浪潮的“参与者”,更是其中的“发力者”,其技术不仅可以用于构建大模型底座,更能对外输出,让国内更多玩家在这一领域具备国际竞争力。
“先上全球AI竞赛的牌桌,才能拥有话语权”
不过,在大模型应用范围日渐扩增、关注度愈发火热的当下,AI行业下一步究竟该如何走,国内外学界和产业巨头中也出现了不一样的声音。
国外玩家中,要属在大模型这一领域进展最快的OpenAI观点最受关注。
作为OpenAI创始人,Sam Altman认为AI技术必将改变世界,因此必须对技术进行监管。
目前,OpenAI已经主动提出对行业接下来要发展的AI技术进行控制,甚至建立对应的国际AI监管机构:
未来十年内,人工智能系统将在很多领域超越专家水平,并且产出能够与当今的最大企业相匹敌。
同样,微软创始人比尔·盖茨也在采访中提到,AI正在给就业医疗等领域带来变革性的影响力,但随着技术发展,监管是必不可少的因素。
不过,马斯克则是直接反对行业继续探索AGI相关的技术,不仅参与签署了“暂停巨型AI实验”的千人联名信,还呼吁暂停更先进的AI系统训练。
显然,在AGI研究日渐火热的当下,要不要继续发展大模型技术,是否会出现“失控”危害人类的超级智能AI,已经成为一个颇具争议性的观点。
作为国内大模型头号玩家的掌舵者,李彦宏如何看待这一话题?
从国际竞争的角度来看,李彦宏认为,在国内外大模型技术发展存在一定差距的当下,发展技术仍旧是优先级最高的选择。
以中国科学家企业家的身份,李彦宏依旧坚信“技术改变世界”的观念:
至少要先上牌桌,赢得全球竞赛的入场券,才能获得话语权,参与规则的制定。
—完—
更新于:2023-05-27 12:36